> ## Documentation Index
> Fetch the complete documentation index at: https://parabola.io/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Extract from email
> Use Parabola's Extract from email step to pull structured data from inbound email attachments (CSV, Excel, PDF, JSON) or the email body, and trigger flows automatically.
The **Extract from email** step gives each flow its own email address. Forward an email there and Parabola pulls in the attachment (CSV, Excel, PDF, or JSON) or the email body itself, then runs the flow. Use it when a vendor, partner, or 3PL already sends you data by email and switching them to an API or shared folder isn't realistic.
## Set up the step
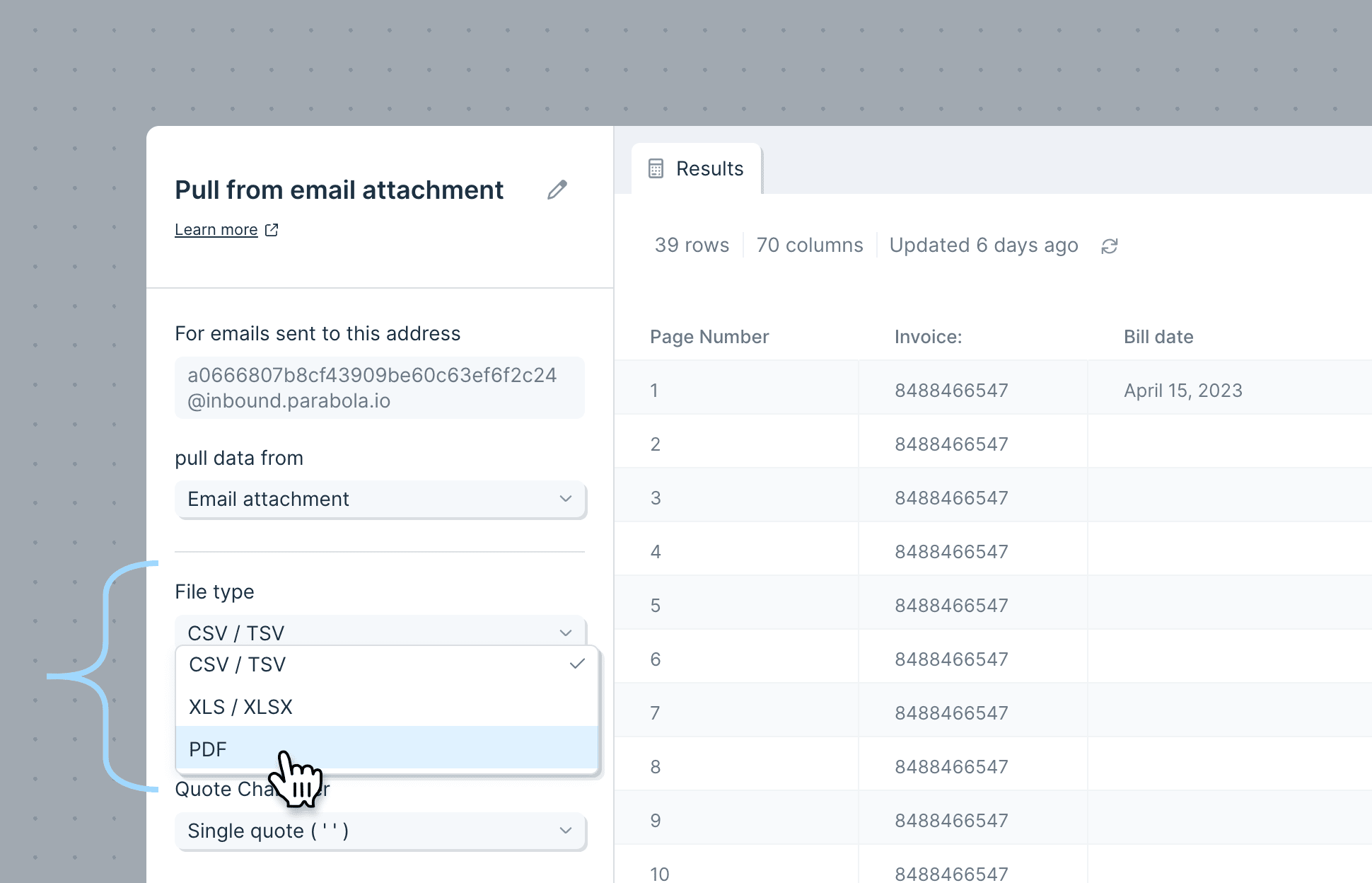
When you add the step to a flow, it generates a unique email address. Copy it and use it as your forwarding destination, or share it with whoever sends the data.
**File Type** defaults to `CSV / TSV`. Other options: `XLS / XLSX`, `PDF`, `JSON`.
For CSV/TSV files, the **Delimiter** defaults to comma; tab and semicolon are also supported. The **Quote Character** defaults to double quote; single quote works too.
In **Advanced settings**, you can skip rows or columns when reading the attachment.
## Auto-forward emails into Parabola
To forward email from outside your domain into Parabola, you'll usually need to verify the `@inbound.parabola.io` address with the sending email service. The Gmail walkthrough below covers the typical flow.
### 1. Prepare the step in Parabola
Drag a new **Extract from email** step into your flow.Configure it to **pull in email content**, not just attachments.Click **Update Results** to save.
Copy the unique email address from the step. You'll paste it into Gmail in the next stage.
### 2. Set up forwarding in Gmail
In Gmail, click the gear icon and choose **See all settings**.Open the **Forwarding and POP/IMAP** tab.Click **Add a forwarding address**.Paste the address from your Parabola step and click **Next → Proceed**.
### 3. Confirm the forwarding request via Parabola
Wait for Gmail's verification email to trigger your flow.Click **View email content** and find the auto-forwarding link.Follow Parabola's prompt to view the external URL.On the Gmail confirmation page, click **Confirm**.
Gmail now recognizes the Parabola address as a valid forwarding destination.
### 4. Filter the emails Gmail forwards
In Gmail, go to **Settings → Filters and Blocked Addresses → Create a new filter**.
Set criteria like:
* **From:** `nycwarehouse@gmail.com`
* **Subject:** `New York City Warehouse Inventory`
* **Has attachment:** checked
Click **Create filter**, check **Forward it to**, choose your verified Parabola address, then click **Create filter**.
### 5. Clean up
If you added a temporary Extract from email step just to verify the forwarding address, delete it. Your real flow will run on filtered, auto-forwarded emails from now on.
### Troubleshooting
If email content isn't showing up after a few minutes, open the email settings on the step (gear icon labeled **view all flow email settings**) and check whether **Reject emails that do not contain valid attachments** is on. If it is, look in your inbox for an email titled "Sorry, we were unable to process your email attachment." Gmail's verification link will be in that email's body. Click it to verify the forwarding address.
## Run the flow once per attachment
By default, the flow runs against the first valid attachment. To process every attachment in a single email, open the **Email trigger settings** modal and choose **Run the flow once per attachment**.
You can change this from the step itself or from the trigger settings on the published flow page. With it on, the flow runs once per file, in order. All files must match the type set in **File type**, otherwise the run errors.
## Pull from the email body
Beyond attachments, the step can pull metadata about the email. Default fields:
* Subject
* Body (plain text)
* CC
* From
* Attached file name
Additional fields:
* Body (HTML)
* Body (all URLs)
* Attached file URL
Switch the **Pull data from** dropdown to **Email content** to access these. To pull both the email body and an attachment, choose **Email content and attachment**.
When **Email content** is selected, you can also turn on **Extract data with AI** under **Parsing settings**. The AI pulls tables and key values out of the email body and returns them as structured columns.
## Pick an Excel sheet by position
For Excel attachments, the **position is** option lets you select a sheet by its index in the workbook instead of its name. Useful when the right data always lives in the same position but the sheet name varies.
The dropdown shows the sheet count from the most recent file. If a future file has fewer sheets than expected, the step errors.
## Tips
* The step runs every time a new file arrives, so you can trigger flows without a schedule or webhook.
* Multi-sheet Excel files default to sheet 1; pick any sheet by name or position.
* Maximum attachment size: 5 MB.
* Each run uses one file. Multiple **Extract from email** steps in the same flow all read from the same email.
* If a flow is mid-run when another email arrives, new emails queue (up to 1,000) and process in order.
* Emails without a valid attachment are rejected by default. Uncheck that setting in the email trigger management modal if you also want to handle attachment-less emails.
* For files linked from inside an email body (rather than attached), Extract from email can read the URL out, but it can't download the file directly. Pass the URL into a [**Run another flow**](/product/integration/parabola-flows) step, start the destination flow with [**Pull from file queue**](/product/integration/pull-from-file-queue), and end it with **Generate CSV file**.
## Extract from Excel files with AI
For messy Excel files where columns shift around or values aren't laid out in a clean grid, **Extract data with AI** pulls tables and individual values reliably. The settings let you pull a table, individual values, or both:
* **Tables** are columns and rows where the first row holds column names.
* **Individual values** are single fields that apply to the whole document — a date at the top, an invoice number, etc.
* Both columns and individual values accept extra context (descriptions, examples, instructions) to improve accuracy.
Once an Excel file is in your flow, select **Extract data with AI**. You'll see options for **Extract a table** and **Extract individual values**. Each step extracts one table plus any number of individual values.
**Extract a table.** Give the table a description so the AI can find the right one when several are present. Then define each column. A clear name (like "Item description") is sometimes enough; for ambiguous names or values, add example cell values and instructions.
**Extract individual values.** Define each value with a name, optional examples, and optional instructions. Same logic as columns: clear names usually work; ambiguous ones benefit from examples.
**Choosing a column or value type.** Columns and values default to Text. Setting a more specific type improves accuracy:
* **Text** — anything
* **True / False** — returns "True" or "False"; useful for checkmarks
* **Number** — strips trailing zeros
* **Currency** — converts the currency to a number
* **Date** — uses `2022-09-27T18:00:00.000` format
* **Signature** — converts signatures to text
* **List of options** — picks from a list you provide
## Extract from PDF files
The PDF parser returns data as **columns** or **keys**:
* **Columns** repeat down the document — line items, rows in a table.
* **Keys** are document-level values that appear once and apply to the whole document — a total, an invoice date.
* The AI sometimes flips the two. If a value isn't pulling correctly, try the other option.
* Both accept extra context to improve accuracy.
The PDF settings below apply across **Extract from email**, [**Extract from PDF**](/product/integration/pdf-file), and [**Pull from file queue**](/product/integration/pull-from-file-queue).
### Pick a parsing method
**Auto-detected table (default).** Parabola scans the PDF and labels likely tables and columns. Best for documents with clear, headered tables. Quickest setup; works best when the file has headers. You can add columns or keys manually after.
**Custom table.** Define the structure by hand if auto-detect didn't catch it. Name the table and add columns with **+ Add Column**. Best for multi-table documents and tables that span multiple pages — more setup, more control.
**Extract all data (OCR-first mode).** Returns all text from the PDF using OCR. Use only when the first two methods fall short. Return formats:
* All data — every value, one per row
* Table data — tables split by page, each with a table ID
* Key-value pairs — labeled items like `SKU: 12345`
* Raw text — one cell per page, useful for follow-up AI parsing
### Extract values
For document-level fields like invoice number or PO date, add them as keys with **+ Add key**. Each key becomes its own column with the value repeated across every row.
* Names can be descriptive — they don't have to match the PDF text exactly.
* Examples are the highest-leverage way to improve accuracy.
* "Additional instructions to find this value" is optional but helpful for tricky cases. Example: to split an order ID like `ABC:123` into two columns, instruct the parser to "Take the order ID and extract all of the characters before the ':' into a new column."
The example below shows the impact of additional instructions on a handwritten YES/NO field.
### Fine tuning
Add overall context and instructions in the fine-tuning text box. Specific examples and clear scenarios beat vague guidance. The chat panel on the left can help you draft the prompt.
### Advanced settings
**Text parsing approach.** Default is "Auto." Other options:
* **OCR** — slower, better for handwriting
* **Markdown** — generally faster, often works better on nested-column documents
**Retry step on error.** On by default. Retries the step once on a transient error.
**Auto-update prompt versions.** Off by default. Parabola occasionally updates the underlying parsing prompts. Because that can shift output, this is opt-in.
**Page filtering.** Off by default. Use it to parse specific pages and speed up runs.
* **Keep, Remove, or Autodetect** — Autodetect lets the parser pick pages
* **The first / the last / these** — set a number for "first" or "last," or list specific pages (e.g., `1, 10, 16`)
### Notes
* Fewer pages parsed = faster runs.
* Multiple tables in one file usually need multiple PDF steps — one per table.
* File limit: under 500 MB and 30 pages.
* PDFs cannot be password protected.
* Always audit AI-parsed results before relying on them.
### Child columns
Mark a column as a "Child column" when its values don't repeat with the parent column — for example, sizes within a product:
**Before:**
**After marking "Size" as a child column:**
### PDF attachments via email
The same PDF parsing options apply when you receive PDFs as email attachments. Configure them on the Extract from email step the same way as on the standalone Extract from PDF step.
For batch-processing many PDFs at once, use [**Pull from file queue**](/product/integration/pull-from-file-queue) instead — it parses PDFs accessible by URL, and runs are added to the queue via API or via [**Run another Parabola flow**](/product/integration/parabola-flows).
## Related steps
* [Extract from PDF](/product/integration/pdf-file) — upload a single PDF and parse it without email forwarding
* [Pull from file queue](/product/integration/pull-from-file-queue) — batch-process many files via URL
* [Email a file attachment](/product/integration/email-attachment) — send the parsed result back out as a file
* [Send emails by row](/product/integration/send-emails) — email per-row results after extraction
* [Run another Parabola flow](/product/integration/parabola-flows) — chain a parsing flow off another flow
* [Extract with AI](/product/transform/extract-with-ai) — pull additional fields from already-parsed text
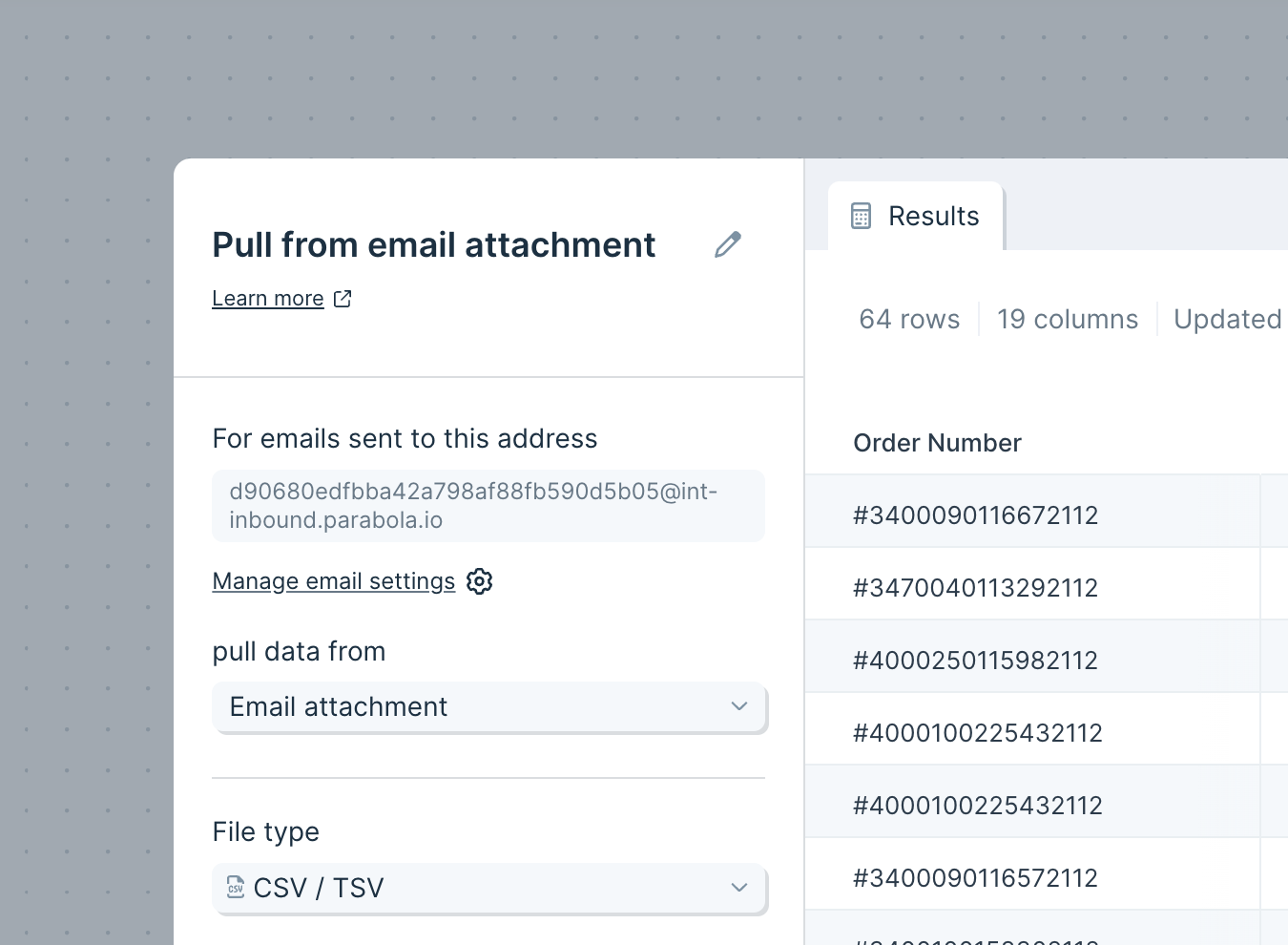 **File Type** defaults to `CSV / TSV`. Other options: `XLS / XLSX`, `PDF`, `JSON`.
For CSV/TSV files, the **Delimiter** defaults to comma; tab and semicolon are also supported. The **Quote Character** defaults to double quote; single quote works too.
**File Type** defaults to `CSV / TSV`. Other options: `XLS / XLSX`, `PDF`, `JSON`.
For CSV/TSV files, the **Delimiter** defaults to comma; tab and semicolon are also supported. The **Quote Character** defaults to double quote; single quote works too.
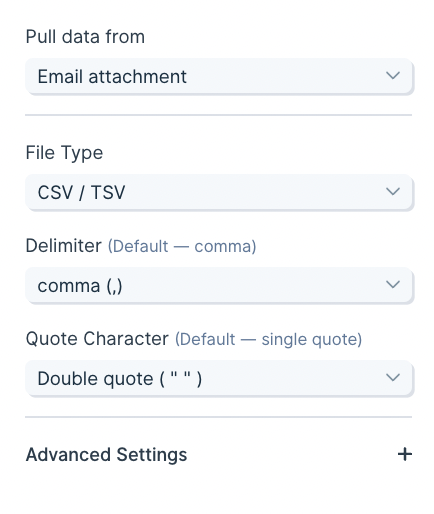 In **Advanced settings**, you can skip rows or columns when reading the attachment.
In **Advanced settings**, you can skip rows or columns when reading the attachment.
 ## Auto-forward emails into Parabola
To forward email from outside your domain into Parabola, you'll usually need to verify the `@inbound.parabola.io` address with the sending email service. The Gmail walkthrough below covers the typical flow.
### 1. Prepare the step in Parabola
## Auto-forward emails into Parabola
To forward email from outside your domain into Parabola, you'll usually need to verify the `@inbound.parabola.io` address with the sending email service. The Gmail walkthrough below covers the typical flow.
### 1. Prepare the step in Parabola
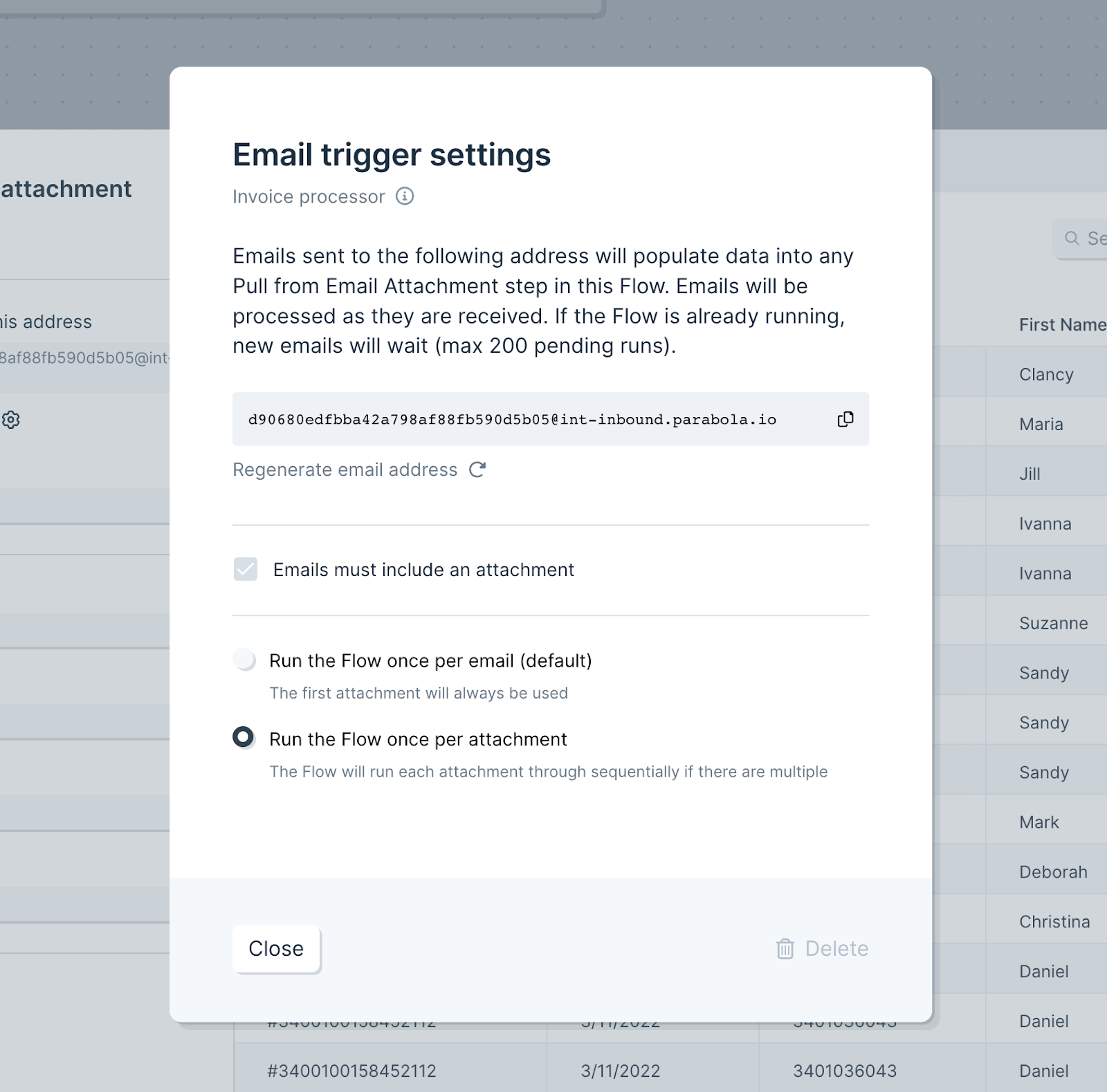 You can change this from the step itself or from the trigger settings on the published flow page. With it on, the flow runs once per file, in order. All files must match the type set in **File type**, otherwise the run errors.
## Pull from the email body
Beyond attachments, the step can pull metadata about the email. Default fields:
* Subject
* Body (plain text)
* CC
* From
* Attached file name
Additional fields:
* Body (HTML)
* Body (all URLs)
* Attached file URL
Switch the **Pull data from** dropdown to **Email content** to access these. To pull both the email body and an attachment, choose **Email content and attachment**.
You can change this from the step itself or from the trigger settings on the published flow page. With it on, the flow runs once per file, in order. All files must match the type set in **File type**, otherwise the run errors.
## Pull from the email body
Beyond attachments, the step can pull metadata about the email. Default fields:
* Subject
* Body (plain text)
* CC
* From
* Attached file name
Additional fields:
* Body (HTML)
* Body (all URLs)
* Attached file URL
Switch the **Pull data from** dropdown to **Email content** to access these. To pull both the email body and an attachment, choose **Email content and attachment**.
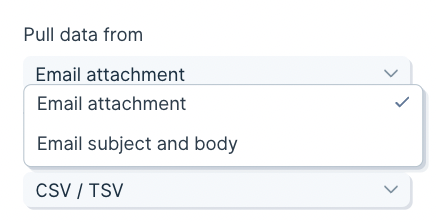 When **Email content** is selected, you can also turn on **Extract data with AI** under **Parsing settings**. The AI pulls tables and key values out of the email body and returns them as structured columns.
## Pick an Excel sheet by position
For Excel attachments, the **position is** option lets you select a sheet by its index in the workbook instead of its name. Useful when the right data always lives in the same position but the sheet name varies.
The dropdown shows the sheet count from the most recent file. If a future file has fewer sheets than expected, the step errors.
When **Email content** is selected, you can also turn on **Extract data with AI** under **Parsing settings**. The AI pulls tables and key values out of the email body and returns them as structured columns.
## Pick an Excel sheet by position
For Excel attachments, the **position is** option lets you select a sheet by its index in the workbook instead of its name. Useful when the right data always lives in the same position but the sheet name varies.
The dropdown shows the sheet count from the most recent file. If a future file has fewer sheets than expected, the step errors.
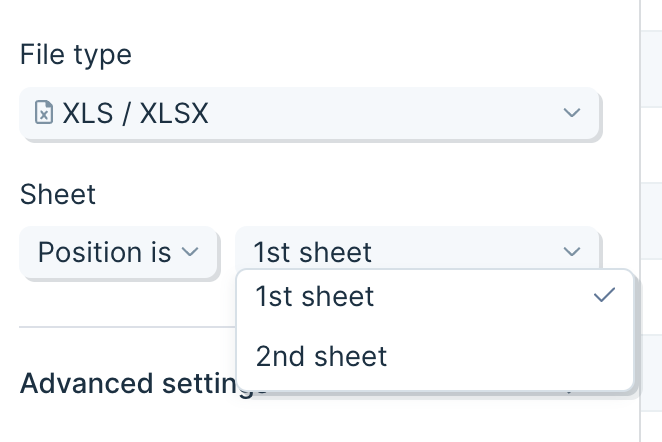 ## Tips
* The step runs every time a new file arrives, so you can trigger flows without a schedule or webhook.
* Multi-sheet Excel files default to sheet 1; pick any sheet by name or position.
* Maximum attachment size: 5 MB.
* Each run uses one file. Multiple **Extract from email** steps in the same flow all read from the same email.
* If a flow is mid-run when another email arrives, new emails queue (up to 1,000) and process in order.
* Emails without a valid attachment are rejected by default. Uncheck that setting in the email trigger management modal if you also want to handle attachment-less emails.
* For files linked from inside an email body (rather than attached), Extract from email can read the URL out, but it can't download the file directly. Pass the URL into a [**Run another flow**](/product/integration/parabola-flows) step, start the destination flow with [**Pull from file queue**](/product/integration/pull-from-file-queue), and end it with **Generate CSV file**.
## Extract from Excel files with AI
For messy Excel files where columns shift around or values aren't laid out in a clean grid, **Extract data with AI** pulls tables and individual values reliably. The settings let you pull a table, individual values, or both:
* **Tables** are columns and rows where the first row holds column names.
* **Individual values** are single fields that apply to the whole document — a date at the top, an invoice number, etc.
* Both columns and individual values accept extra context (descriptions, examples, instructions) to improve accuracy.
Once an Excel file is in your flow, select **Extract data with AI**. You'll see options for **Extract a table** and **Extract individual values**. Each step extracts one table plus any number of individual values.
## Tips
* The step runs every time a new file arrives, so you can trigger flows without a schedule or webhook.
* Multi-sheet Excel files default to sheet 1; pick any sheet by name or position.
* Maximum attachment size: 5 MB.
* Each run uses one file. Multiple **Extract from email** steps in the same flow all read from the same email.
* If a flow is mid-run when another email arrives, new emails queue (up to 1,000) and process in order.
* Emails without a valid attachment are rejected by default. Uncheck that setting in the email trigger management modal if you also want to handle attachment-less emails.
* For files linked from inside an email body (rather than attached), Extract from email can read the URL out, but it can't download the file directly. Pass the URL into a [**Run another flow**](/product/integration/parabola-flows) step, start the destination flow with [**Pull from file queue**](/product/integration/pull-from-file-queue), and end it with **Generate CSV file**.
## Extract from Excel files with AI
For messy Excel files where columns shift around or values aren't laid out in a clean grid, **Extract data with AI** pulls tables and individual values reliably. The settings let you pull a table, individual values, or both:
* **Tables** are columns and rows where the first row holds column names.
* **Individual values** are single fields that apply to the whole document — a date at the top, an invoice number, etc.
* Both columns and individual values accept extra context (descriptions, examples, instructions) to improve accuracy.
Once an Excel file is in your flow, select **Extract data with AI**. You'll see options for **Extract a table** and **Extract individual values**. Each step extracts one table plus any number of individual values.
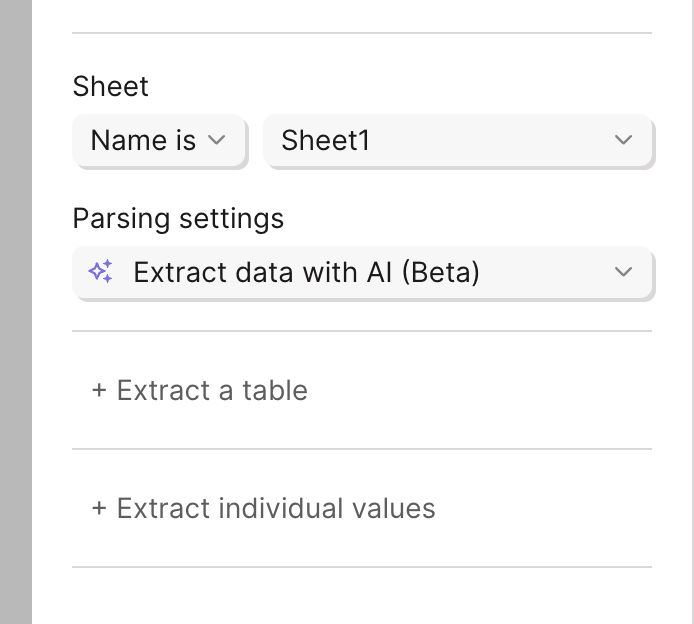 **Extract a table.** Give the table a description so the AI can find the right one when several are present. Then define each column. A clear name (like "Item description") is sometimes enough; for ambiguous names or values, add example cell values and instructions.
**Extract individual values.** Define each value with a name, optional examples, and optional instructions. Same logic as columns: clear names usually work; ambiguous ones benefit from examples.
**Choosing a column or value type.** Columns and values default to Text. Setting a more specific type improves accuracy:
* **Text** — anything
* **True / False** — returns "True" or "False"; useful for checkmarks
* **Number** — strips trailing zeros
* **Currency** — converts the currency to a number
* **Date** — uses `2022-09-27T18:00:00.000` format
* **Signature** — converts signatures to text
* **List of options** — picks from a list you provide
## Extract from PDF files
The PDF parser returns data as **columns** or **keys**:
* **Columns** repeat down the document — line items, rows in a table.
* **Keys** are document-level values that appear once and apply to the whole document — a total, an invoice date.
* The AI sometimes flips the two. If a value isn't pulling correctly, try the other option.
* Both accept extra context to improve accuracy.
The PDF settings below apply across **Extract from email**, [**Extract from PDF**](/product/integration/pdf-file), and [**Pull from file queue**](/product/integration/pull-from-file-queue).
### Pick a parsing method
**Auto-detected table (default).** Parabola scans the PDF and labels likely tables and columns. Best for documents with clear, headered tables. Quickest setup; works best when the file has headers. You can add columns or keys manually after.
**Custom table.** Define the structure by hand if auto-detect didn't catch it. Name the table and add columns with **+ Add Column**. Best for multi-table documents and tables that span multiple pages — more setup, more control.
**Extract all data (OCR-first mode).** Returns all text from the PDF using OCR. Use only when the first two methods fall short. Return formats:
* All data — every value, one per row
* Table data — tables split by page, each with a table ID
* Key-value pairs — labeled items like `SKU: 12345`
* Raw text — one cell per page, useful for follow-up AI parsing
### Extract values
For document-level fields like invoice number or PO date, add them as keys with **+ Add key**. Each key becomes its own column with the value repeated across every row.
* Names can be descriptive — they don't have to match the PDF text exactly.
* Examples are the highest-leverage way to improve accuracy.
* "Additional instructions to find this value" is optional but helpful for tricky cases. Example: to split an order ID like `ABC:123` into two columns, instruct the parser to "Take the order ID and extract all of the characters before the ':' into a new column."
The example below shows the impact of additional instructions on a handwritten YES/NO field.
**Extract a table.** Give the table a description so the AI can find the right one when several are present. Then define each column. A clear name (like "Item description") is sometimes enough; for ambiguous names or values, add example cell values and instructions.
**Extract individual values.** Define each value with a name, optional examples, and optional instructions. Same logic as columns: clear names usually work; ambiguous ones benefit from examples.
**Choosing a column or value type.** Columns and values default to Text. Setting a more specific type improves accuracy:
* **Text** — anything
* **True / False** — returns "True" or "False"; useful for checkmarks
* **Number** — strips trailing zeros
* **Currency** — converts the currency to a number
* **Date** — uses `2022-09-27T18:00:00.000` format
* **Signature** — converts signatures to text
* **List of options** — picks from a list you provide
## Extract from PDF files
The PDF parser returns data as **columns** or **keys**:
* **Columns** repeat down the document — line items, rows in a table.
* **Keys** are document-level values that appear once and apply to the whole document — a total, an invoice date.
* The AI sometimes flips the two. If a value isn't pulling correctly, try the other option.
* Both accept extra context to improve accuracy.
The PDF settings below apply across **Extract from email**, [**Extract from PDF**](/product/integration/pdf-file), and [**Pull from file queue**](/product/integration/pull-from-file-queue).
### Pick a parsing method
**Auto-detected table (default).** Parabola scans the PDF and labels likely tables and columns. Best for documents with clear, headered tables. Quickest setup; works best when the file has headers. You can add columns or keys manually after.
**Custom table.** Define the structure by hand if auto-detect didn't catch it. Name the table and add columns with **+ Add Column**. Best for multi-table documents and tables that span multiple pages — more setup, more control.
**Extract all data (OCR-first mode).** Returns all text from the PDF using OCR. Use only when the first two methods fall short. Return formats:
* All data — every value, one per row
* Table data — tables split by page, each with a table ID
* Key-value pairs — labeled items like `SKU: 12345`
* Raw text — one cell per page, useful for follow-up AI parsing
### Extract values
For document-level fields like invoice number or PO date, add them as keys with **+ Add key**. Each key becomes its own column with the value repeated across every row.
* Names can be descriptive — they don't have to match the PDF text exactly.
* Examples are the highest-leverage way to improve accuracy.
* "Additional instructions to find this value" is optional but helpful for tricky cases. Example: to split an order ID like `ABC:123` into two columns, instruct the parser to "Take the order ID and extract all of the characters before the ':' into a new column."
The example below shows the impact of additional instructions on a handwritten YES/NO field.
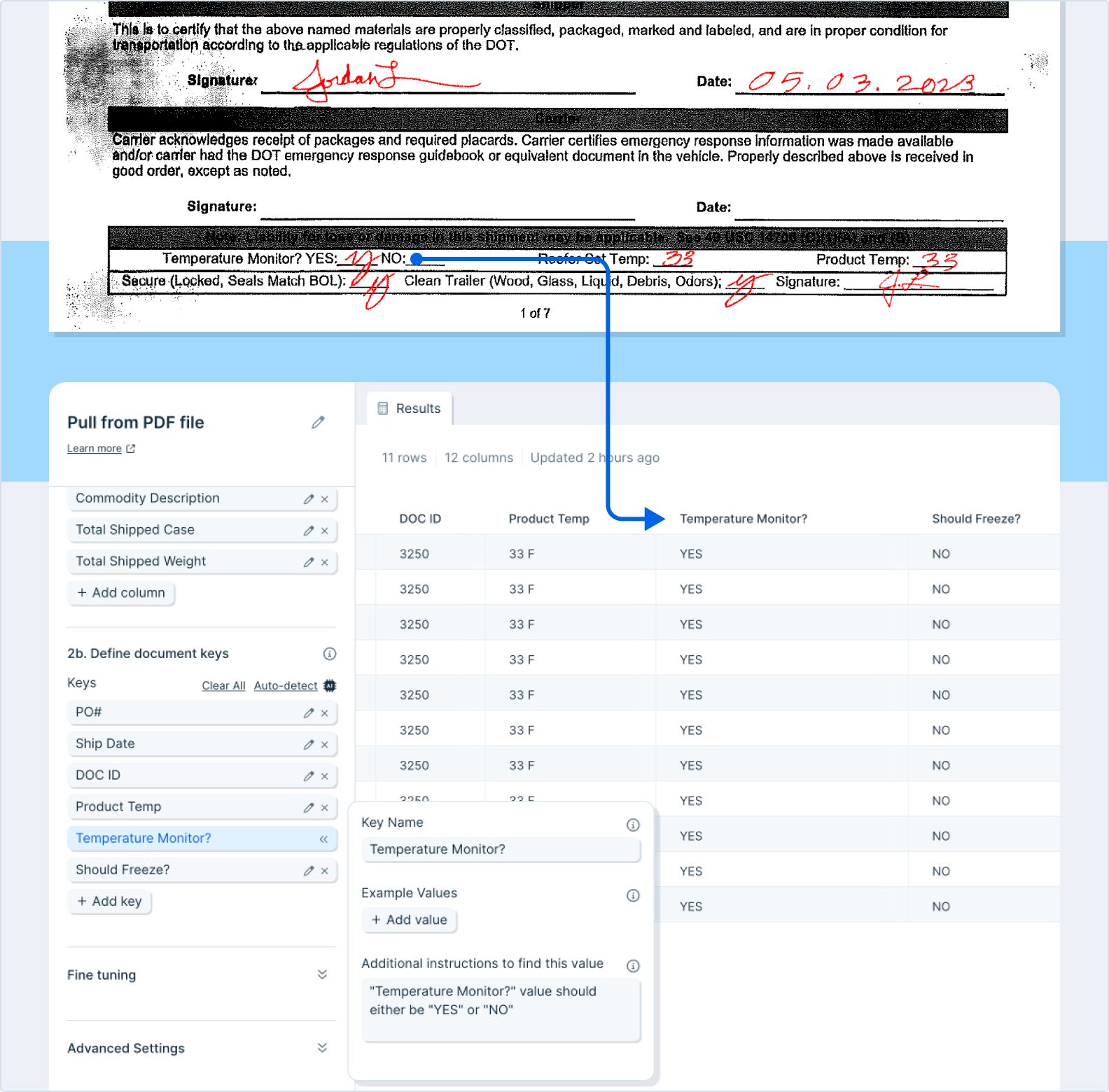 ### Fine tuning
Add overall context and instructions in the fine-tuning text box. Specific examples and clear scenarios beat vague guidance. The chat panel on the left can help you draft the prompt.
### Advanced settings
**Text parsing approach.** Default is "Auto." Other options:
* **OCR** — slower, better for handwriting
* **Markdown** — generally faster, often works better on nested-column documents
**Retry step on error.** On by default. Retries the step once on a transient error.
**Auto-update prompt versions.** Off by default. Parabola occasionally updates the underlying parsing prompts. Because that can shift output, this is opt-in.
**Page filtering.** Off by default. Use it to parse specific pages and speed up runs.
* **Keep, Remove, or Autodetect** — Autodetect lets the parser pick pages
* **The first / the last / these** — set a number for "first" or "last," or list specific pages (e.g., `1, 10, 16`)
### Notes
* Fewer pages parsed = faster runs.
* Multiple tables in one file usually need multiple PDF steps — one per table.
* File limit: under 500 MB and 30 pages.
* PDFs cannot be password protected.
* Always audit AI-parsed results before relying on them.
### Child columns
Mark a column as a "Child column" when its values don't repeat with the parent column — for example, sizes within a product:
**Before:**
### Fine tuning
Add overall context and instructions in the fine-tuning text box. Specific examples and clear scenarios beat vague guidance. The chat panel on the left can help you draft the prompt.
### Advanced settings
**Text parsing approach.** Default is "Auto." Other options:
* **OCR** — slower, better for handwriting
* **Markdown** — generally faster, often works better on nested-column documents
**Retry step on error.** On by default. Retries the step once on a transient error.
**Auto-update prompt versions.** Off by default. Parabola occasionally updates the underlying parsing prompts. Because that can shift output, this is opt-in.
**Page filtering.** Off by default. Use it to parse specific pages and speed up runs.
* **Keep, Remove, or Autodetect** — Autodetect lets the parser pick pages
* **The first / the last / these** — set a number for "first" or "last," or list specific pages (e.g., `1, 10, 16`)
### Notes
* Fewer pages parsed = faster runs.
* Multiple tables in one file usually need multiple PDF steps — one per table.
* File limit: under 500 MB and 30 pages.
* PDFs cannot be password protected.
* Always audit AI-parsed results before relying on them.
### Child columns
Mark a column as a "Child column" when its values don't repeat with the parent column — for example, sizes within a product:
**Before:**
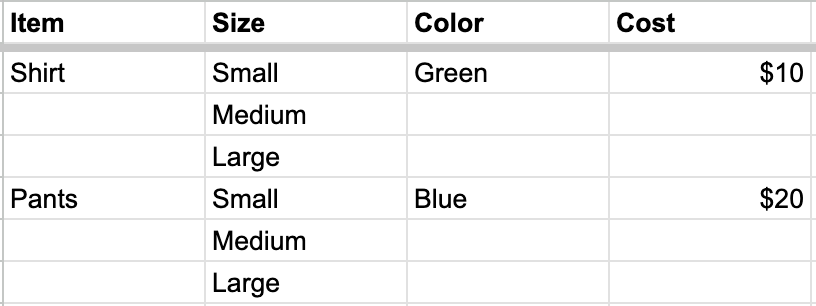 **After marking "Size" as a child column:**
**After marking "Size" as a child column:**
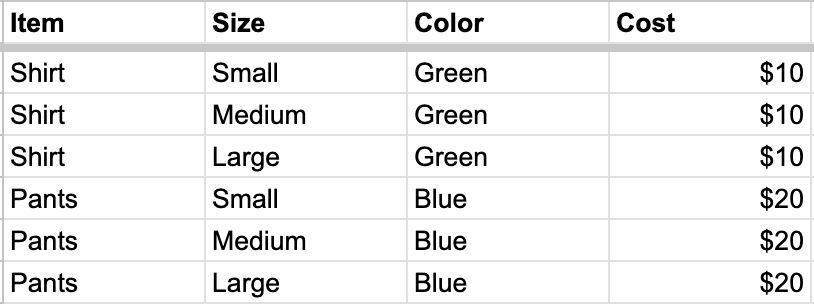 ### PDF attachments via email
The same PDF parsing options apply when you receive PDFs as email attachments. Configure them on the Extract from email step the same way as on the standalone Extract from PDF step.
### PDF attachments via email
The same PDF parsing options apply when you receive PDFs as email attachments. Configure them on the Extract from email step the same way as on the standalone Extract from PDF step.
 For batch-processing many PDFs at once, use [**Pull from file queue**](/product/integration/pull-from-file-queue) instead — it parses PDFs accessible by URL, and runs are added to the queue via API or via [**Run another Parabola flow**](/product/integration/parabola-flows).
## Related steps
* [Extract from PDF](/product/integration/pdf-file) — upload a single PDF and parse it without email forwarding
* [Pull from file queue](/product/integration/pull-from-file-queue) — batch-process many files via URL
* [Email a file attachment](/product/integration/email-attachment) — send the parsed result back out as a file
* [Send emails by row](/product/integration/send-emails) — email per-row results after extraction
* [Run another Parabola flow](/product/integration/parabola-flows) — chain a parsing flow off another flow
* [Extract with AI](/product/transform/extract-with-ai) — pull additional fields from already-parsed text
For batch-processing many PDFs at once, use [**Pull from file queue**](/product/integration/pull-from-file-queue) instead — it parses PDFs accessible by URL, and runs are added to the queue via API or via [**Run another Parabola flow**](/product/integration/parabola-flows).
## Related steps
* [Extract from PDF](/product/integration/pdf-file) — upload a single PDF and parse it without email forwarding
* [Pull from file queue](/product/integration/pull-from-file-queue) — batch-process many files via URL
* [Email a file attachment](/product/integration/email-attachment) — send the parsed result back out as a file
* [Send emails by row](/product/integration/send-emails) — email per-row results after extraction
* [Run another Parabola flow](/product/integration/parabola-flows) — chain a parsing flow off another flow
* [Extract with AI](/product/transform/extract-with-ai) — pull additional fields from already-parsed text