New
Restrict integrations to credential owners
Org Admins can now set any integration to "Restricted" from the Integration Management page. When an integration is restricted, only the user who owns the credentials used to authorize it can edit the step's settings. Teammates who open a shared flow with a restricted step will see a read-only view, with the option to switch to their own credentials or create a new authorization. This ensures that only the authorized user can control what data is imported or exported through an integration they've set up.
New
Integration Management page for Org Admins
Org Admins on Advanced and Enterprise plans can now control which integrations are available across their organization from a new Integration Management page. Set any integration to enabled, restricted, or disabled. Restricted integrations limit step editing to the credential owner, while disabled integrations block usage entirely.
New
Stream audit logs to your SIEM
Enterprise teams can now stream Parabola audit logs in real time to their own infrastructure for ingestion into SIEM tooling. Get full visibility into user authentication, flow modifications, access events, and more.
Improvement
Auto-layout now works with cards
The auto-layout button now supports flows that use cards. Hit the auto-layout button in the bottom corner of the flow canvas to instantly organize even your most complex flows - cards and all.
New
New Parabola docs experience
We've launched a completely redesigned documentation site at parabola.io/docs. Search across all of our documentation, ask questions with "Ask AI," and enjoy a cleaner, faster browsing experience. A new home for Parabola University with new content coming very soon!
New
Access invoices and receipts on the billing page
All invoices and receipts are now available directly on the billing page - no more waiting for PDFs to be sent manually. Admins will also see a new banner when invoices are past due, with a direct link to take action.
New
Talk to chat sidebar
You can now talk to the chat sidebar using your voice. Chat with Parabola's AI builder out loud for a faster, more natural building experience. Currently available in Chrome browsers.

New
Pin cells, rows, and columns in the result view
Click any cell to highlight its row, or click a column header to highlight the entire column. Highlights are durable — they stick as you scroll and navigate, making it easier to track specific data across large datasets.

Improvement
Export XML files via FTP
The Send to FTP step now supports XML as an export file type. Place your XML content in a single column, and the step handles the rest - including merge tags for dynamic file names and folder paths, validation to catch errors before export, and the ability to export up to 50 files per run.
Fix
Flow queue panel fix
We fixed an issue where pausing and then clearing a flow's run queue would permanently hide the queue panel, locking you out from resuming. The panel now stays visible whenever the queue is paused, so you can always resume.
Improvement
Custom transform step now supports multiple inputs and locked columns
The Custom transform step just got two big upgrades. Steps can now accept up to 5 input tables, making it easier to work across multiple datasets in a single step. You can also lock output columns in place so that regenerating or editing your logic won't change the structure of your results.

Improvement
Format numbers now reads accounting format
The Format numbers step can now read accounting-formatted numbers like ($100) and transform them into any other format. No more workarounds with Find & replace. If you're working with accounting data, format it first with this step and then use it throughout your flow.
Improvement
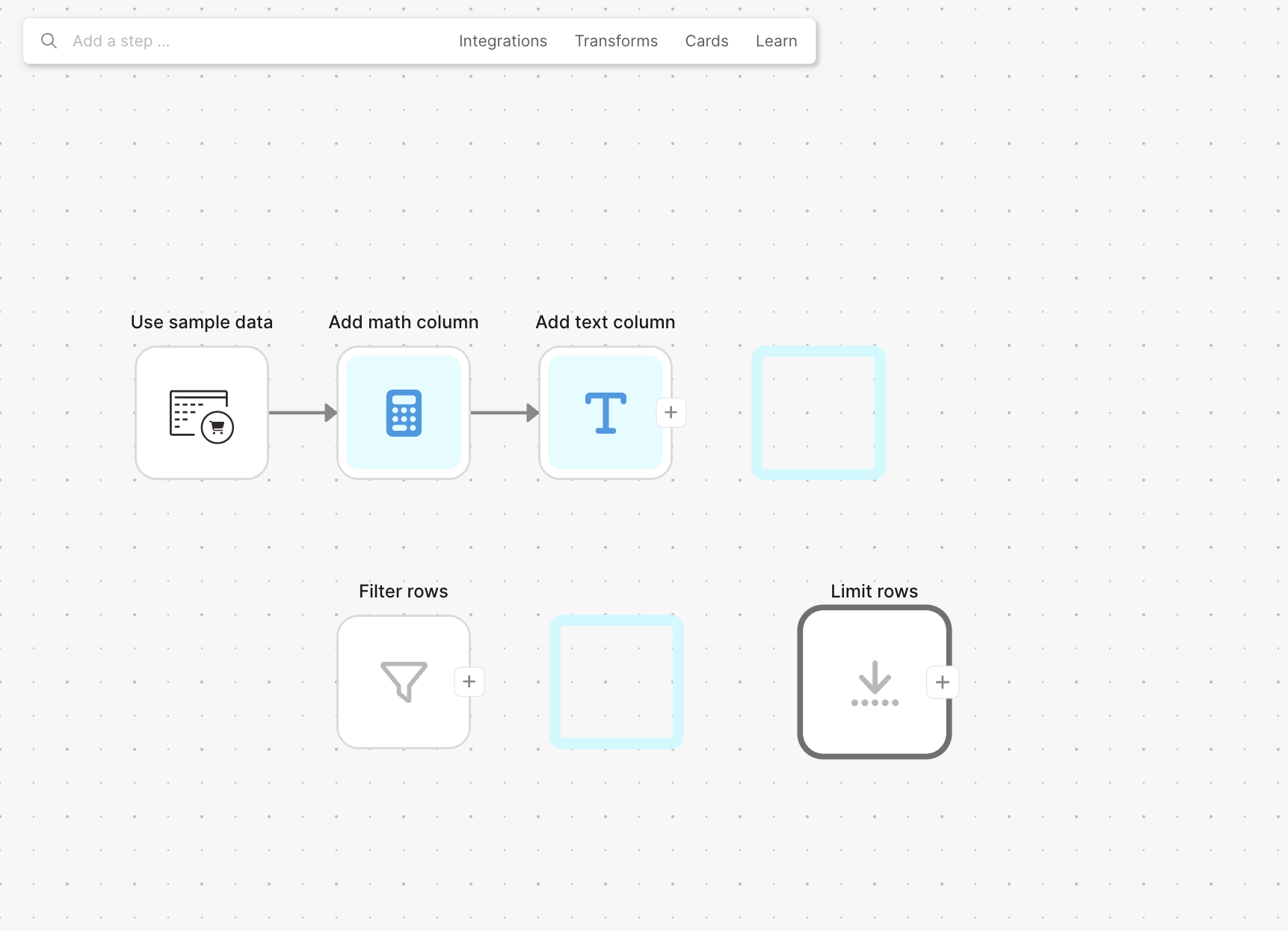
Step placemats now available throughout the flow building experience
Step placemats make flow building faster: drop a step onto a placemat and arrows connect instantly. Previously only available when dragging from the step search bar, placemats now appear whenever you're moving disconnected steps around the canvas.
Improvement
Deleting steps automatically reconnects the flow
When you delete a step, we now automatically reconnect the surrounding steps. Delete B from A → B → C and we'll reconnect A → C for you.
Fix
Send Email by Row column variables error
We fixed an issue with the Send Email by Row step where emails would fail if your data cells contained curly brackets {}. We also improved error messages to now show exactly which variable is missing and where it's located, making troubleshooting easier.
Improvement
Parabola now builds with GPT-5.2
We updated our AI chat sidebar to use GPT-5.2. You can expect faster and more accurate replies!
Improvement
Access native browser context menus on cards
You can now access your standard browser context menu by right-clicking text within cards. Use it to quickly copy/paste, correct spelling, or use browser extensions directly on your card text.

New
Restrict visibility for sensitive Looker fields
Credential owners can now take an additional step to hide sensitive Looker fields from the broader team. Simply check the new visibility toggle to ensure fields like Client Data remain private while still allowing your team to use the account on their flows.
Fix
Superbar hotkey is back
The "S" hotkey is back in action. Press "S" at any time to instantly open the Superbar and search for steps.
Fix
Microsoft Dynamics double-calculation fix
Resolved a bug where the Microsoft Dynamics step would occasionally calculate twice when opened for configuration. We’re also rolling out system-wide improvements to prevent redundant refreshes across other steps soon.
Fix
Parabola Table naming
We fixed a bug where Parabola Table names weren’t saving correctly, causing them to appear as “Uninitialized table” in dropdown menus. Your tables will now correctly display their assigned names everywhere they appear.
Improvement
Improved inactivity handling
If you’ve been away from your flow for a while, we’ll no longer automatically kick you back to the Flows page. Instead, you’ll see a helpful banner prompting you to refresh the page so you can pick up exactly where you left off.

Improvement
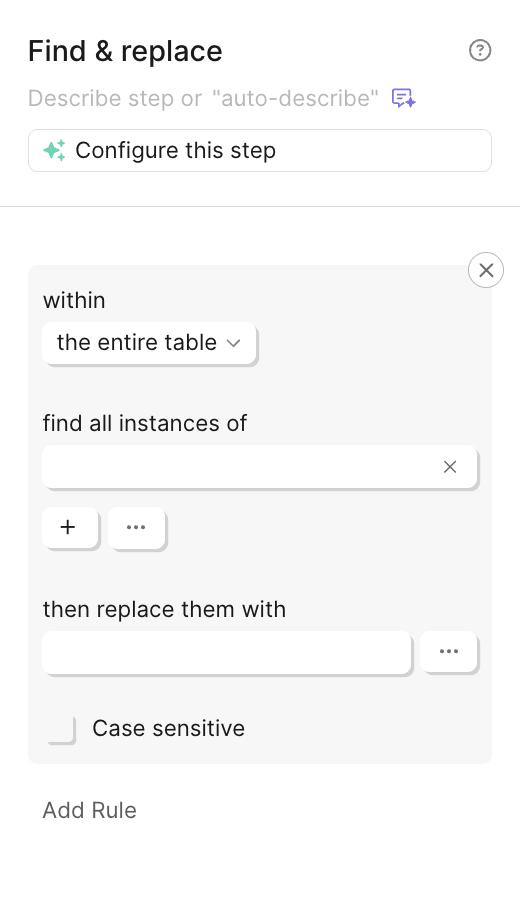
Larger Find & Replace input
The Find & Replace text boxes are finally bigger! You now have much more room to see exactly what you’re searching for and what you’re replacing it with.
Improvement
A better scrolling experience
We’ve made two key updates to help you navigate your flows more smoothly:
- Permanent scrollbars on results: We’ve made the horizontal scrollbar permanent so you can seamlessly navigate large datasets—especially helpful for non-trackpad users.
- Canvas "Swipe-to-Exit" protection: We’ve addressed an issue where scrolling horizontally on the canvas and step results view could accidentally trigger a "back" gesture and exit your flow. Now, you can move around your step results and canvas freely without losing your spot.
Improvement
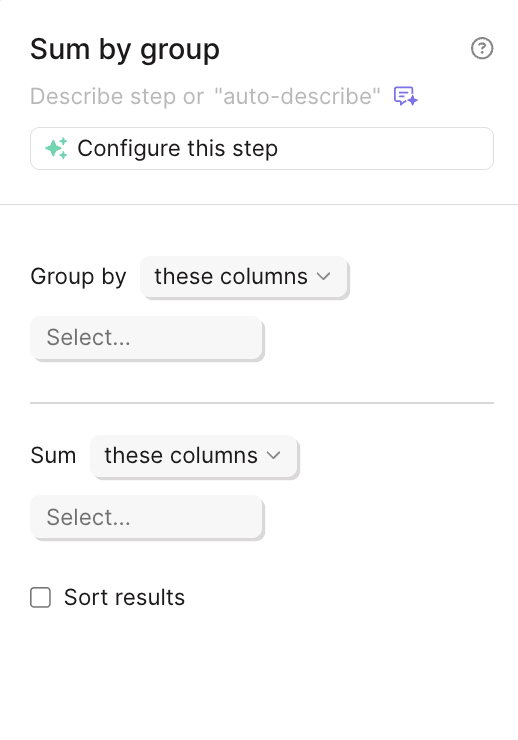
Intuitive configuration for Sum & Average by Group
We’ve swapped the configuration settings in the Sum by Group and Average by Group steps to better align with how you intuitively build. This small change makes these steps faster and more logical to set up.
Improvement
Instant access to duplicated flows
When you duplicate a flow, Parabola will now automatically open the new copy in a separate tab.
New
30+ new integrations, now live
Connecting the tools you rely on continues to get easier. Find key integrations in the latest batch of releases, including:
- ERP: Cin7, Send to NetSuite
- Shipping & visibility: AfterShip & Flexport
- Support & marketing: Kustomer, Gorgias, Klaviyo
- Returns & subscriptions: Loop, Recharge
- Finance: Coupa, Live Currency Conversion
- Data: Metabase, Coda, Send to Redshift
- WMS: DCL Logistics
Just search for the integration in Parabola to get started. Check out our docs for more integration-specific info, and explore the full list of recent releases below.

Improvement
Calculate dates dynamically
In the Add date & time step, you can now use a {merge tag} to dynamically calculate dates based on the value in another column.
This is especially useful for SLA analysis: calculate your “Ship by date” by offsetting the “Order date” based on the number of “Days to ship.”

Improvement
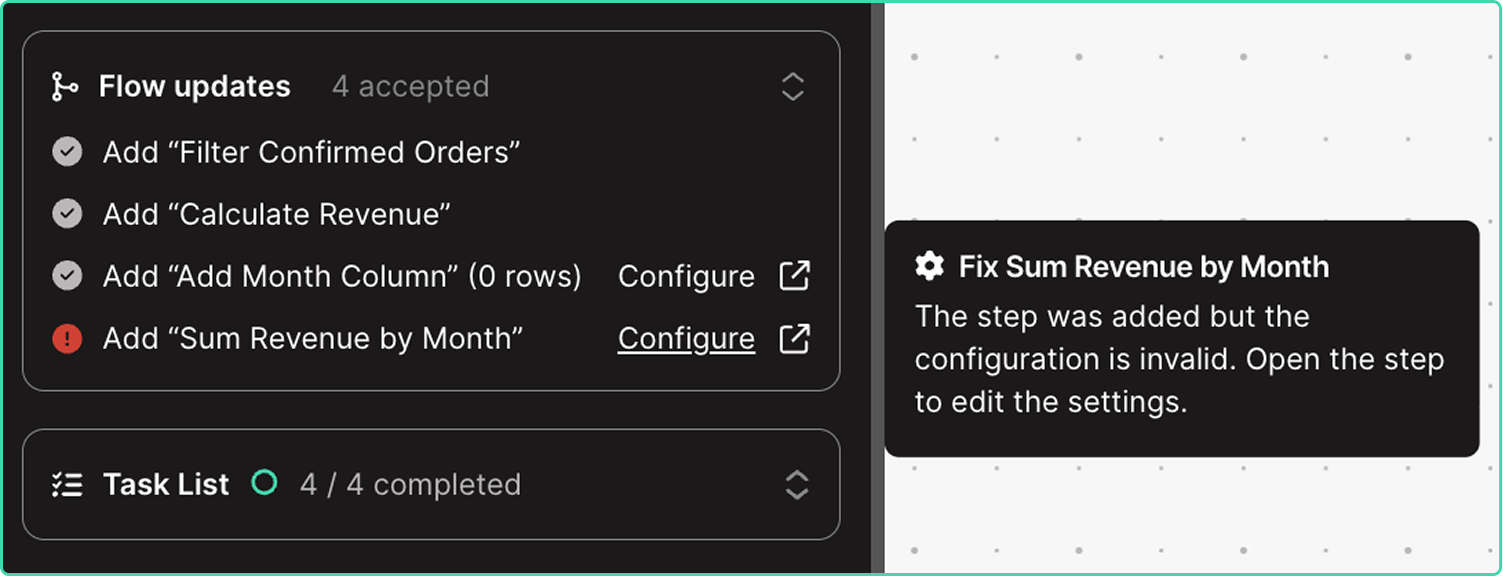
Enhanced visibility into agent updates
The easiest way to build in Parabola is by sending chat messages, prompting Parabola to add and update steps directly on the canvas. You can now track the status of AI-implemented changes in the chat and immediately take action on steps requiring updates.
New
10+ new integrations, now live
Accessing operational data should be fast and easy. To bring that aspiration to life, we’re excited to introduce 13 new integrations with 20+ more launching before EOY:
- ERPs: Fulfil and Microsoft Dynamics (Finance & Operations)
- Carriers & shipment tracking: Fedex, UPS, EasyPost, and Jitsu
- WMSs: ShipMonk, ShipBob, Stord, InfoPlus
- Return platforms: Frate Returns
- Ticketing: Zendesk
- PO management: Sage Supply Chain Intelligence
Click here to explore docs & demos.

New
🔊 30+ new integrations are coming to Parabola
Once your data is connected, building flows in Parabola becomes pretty magical. And as you connect more sources, your flows become more powerful and informed.
But that first step—connecting your sources—is often the hardest step in the process.
Over the next two months, we're rolling out 30+ highly-requested integrations spanning ERPs, return platforms, WMS systems, data warehouses, and CX tools.
Up first: use our new UPS and Fedex integrations to track shipments, store historical data for scorecarding, and action on errors and exceptions in real-time.
Want to keep up with the launches? Follow Parabola on LinkedIn to stay in the loop.
Improvement
Perform advanced math calculations
We’ve upgraded the Add math column and Add if/else column steps to support more complex formulas. You can now perform advanced calculations using new functions like abs(), round(), min(), max(), mean(), median(), std(), and more.

Improvement
Prevent failing flows from pausing
Within a flow’s settings, you can now set a flow to continue running even after 10 consecutive failed runs.
Improvement
Send unbranded emails from Parabola
Within the “Email a file attachment” step, you can now use a plain text option to remove Parabola branding from the body of an email.
Improvement
Dynamically name Google Drive files
You can now insert merge tags in the “Send to Google Drive” to dynamically name files as they’re created.
New
Write and optimize queries with AI
Across all database steps, you can now “Write” and “Optimize” queries using plain language. Skip the SQL headaches and let Parabola handle your query complexity.
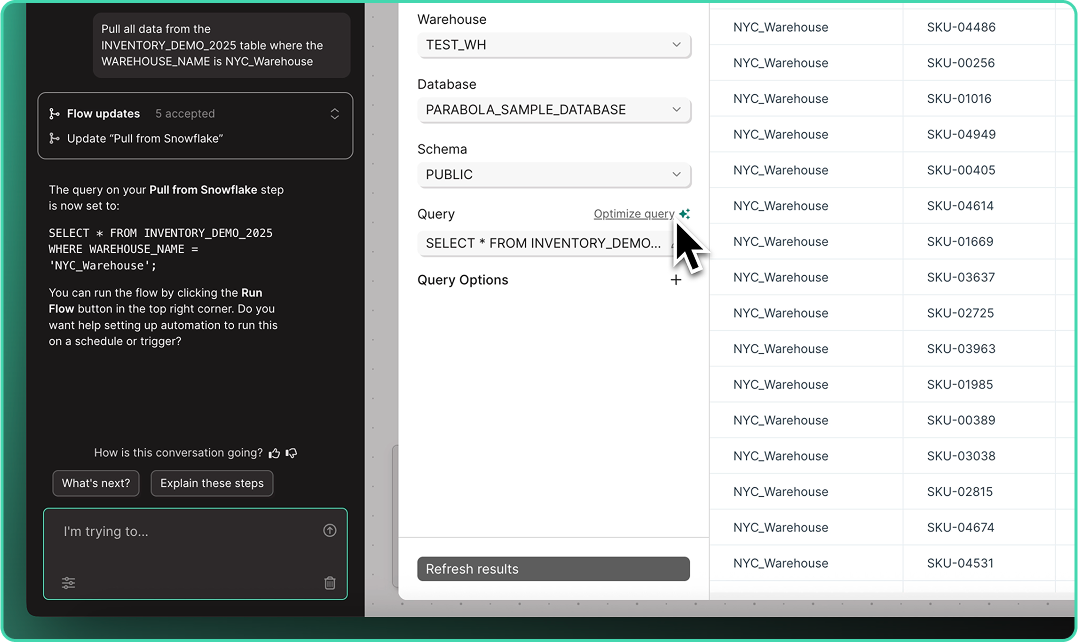
Improvement
Quickly connect your go-to accounts
After saving an integration account, users can now specify a “default” account across their integrations. Once set, your default account is automatically selected every time you drop a new step in any flow.
Note: Defaults are set at the user-level, so every user can select their own defaults.

Improvement
Build with AI every step of the way
Say goodbye to the blank canvas. Describe what you need or choose a use case, and let AI help you execute tasks with smart, contextual suggestions guiding you from start to finish.
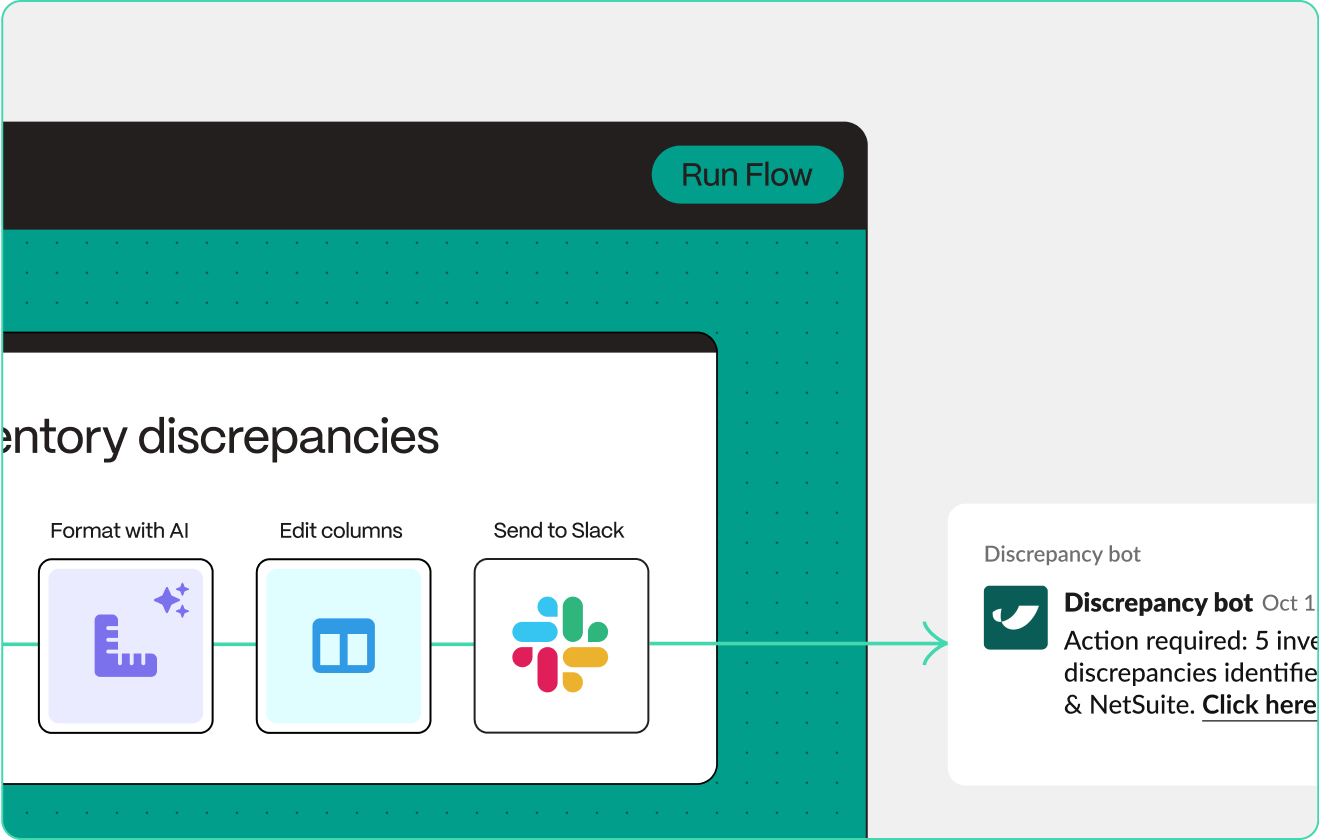
New
Real-time updates, straight to Slack
With our new Send to Slack step, you can connect your systems to Slack in seconds to keep tabs on the important data running throughout your stack.
Automatically DM users or send channel updates, include CSV files and images, and customize messages with variables to share the right data, at the right time.
Check out the announcement post to learn about how brands like Bandit and Vacation Inc. are putting this step to work!
Improvement
Connectivity for XLSB and XLSM files
You can now import .XLSB and .XLSM files using the Pull from Excel and Extract from email steps—expanding the collection of supported file formats.
Improvement
Intuitively combine datasets
A long-standing behavior has been updated: arrows connected to the Combine tables step can now be disconnected and reattached without breaking the step configuration. This means smoother adjustments when reorganizing upstream steps, regardless of connection order.
Improvement
More resilient and flexible FTP connections
The Pull from FTP step now runs successfully even when folders are empty—using headers from the last file processed. The Send to FTP step also supports a new dynamic file naming option: {timestampDash}. Learn more here.
New
Connect your flow with the web
Parabola can now search the web to give you more accurate, informed answers. Get up-to-date intel on API docs, error codes, third-party data nuances, and more so you can build faster without jumping between tabs.
%2520small%25204.gif)
Improvement
Optimize prompts and trust your Custom transforms
The Custom transform step just got three major upgrades. Use the new Optimize this prompt✨ button to instantly improve your prompts and improve results. Now 3x more reliable with clearer, more actionable error messages so you can fix and fine tune faster.
Learn more in the new Parabola University lesson.

New
Stop flow runs and get back to building
You can now cancel a flow mid-run and make updates instantly. If you spot a mistake or a run takes longer than expected, hit the “Stop run” button and get back to building without the wait.
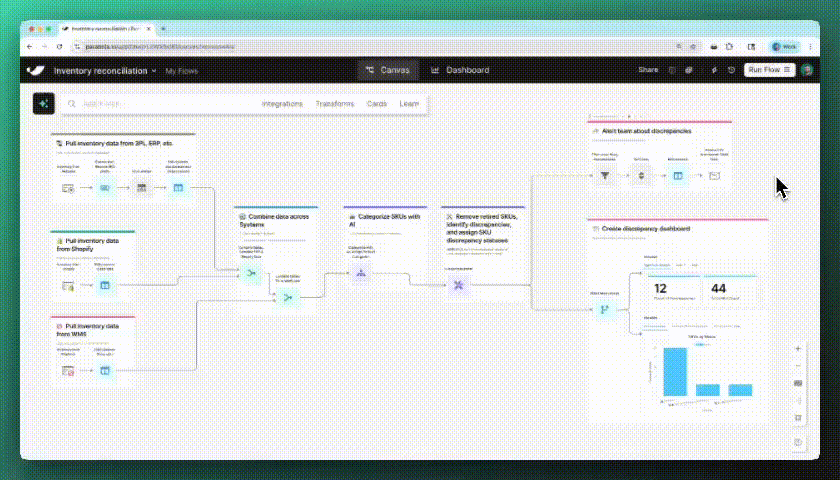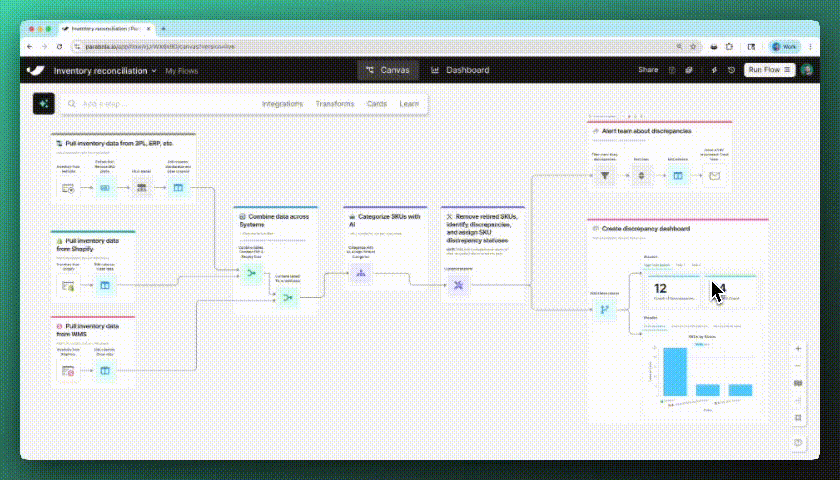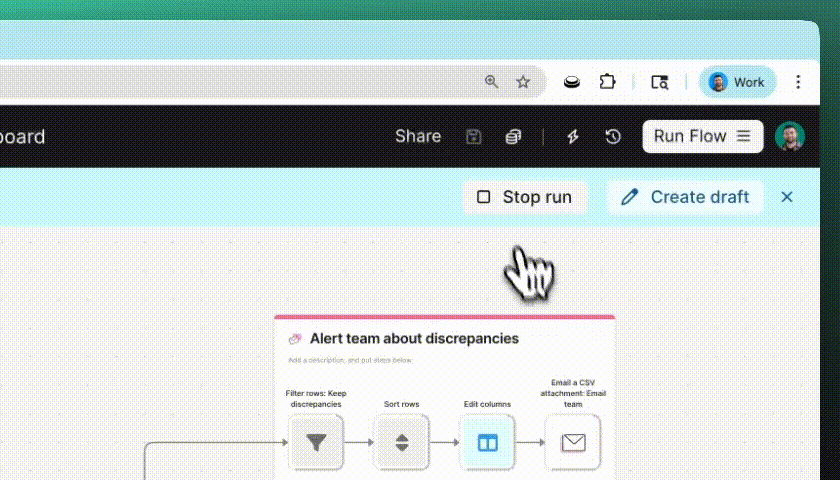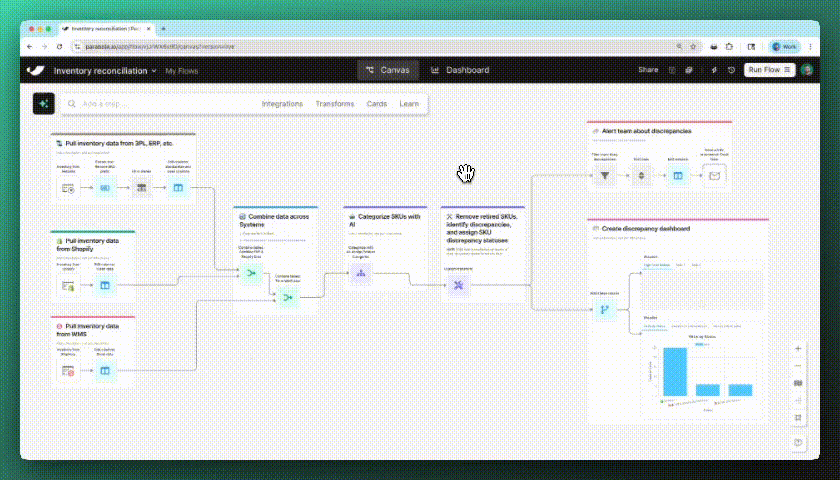
Improvement
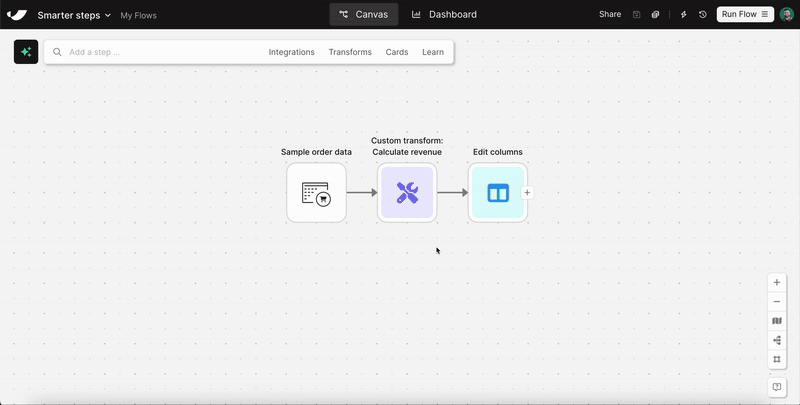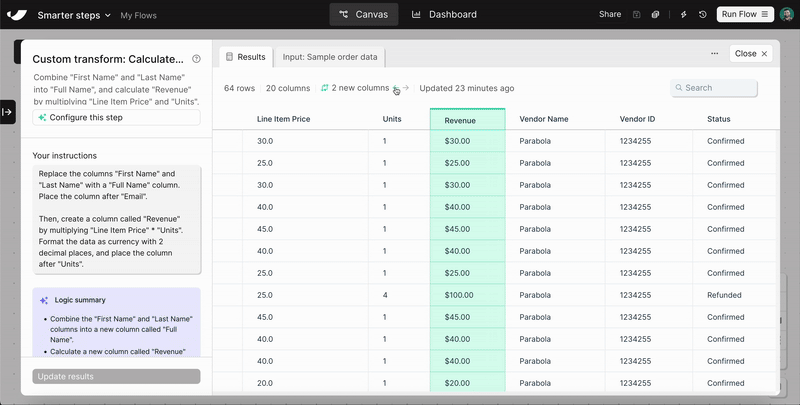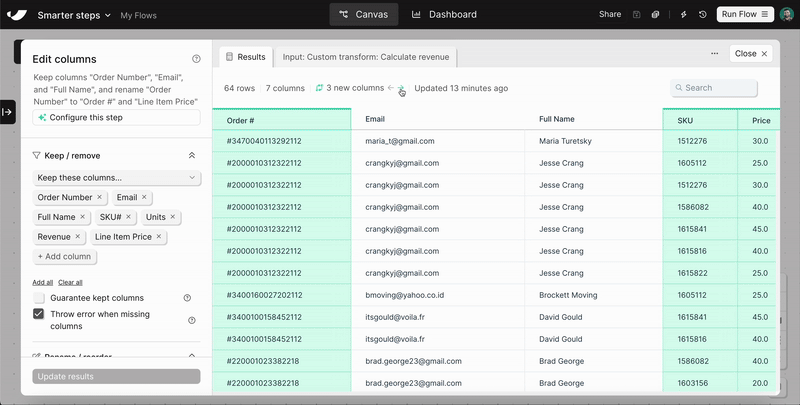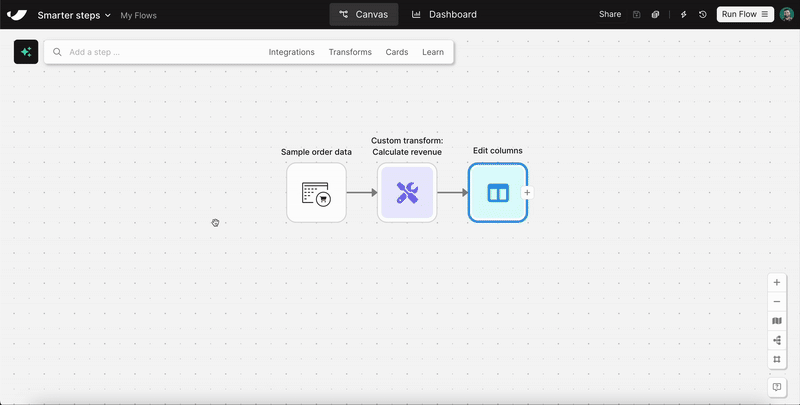
Spot changes instantly
Parabola now highlights exactly what changed in each step. New and edited columns are automatically spotlighted in a refreshed data grid, so you can easily follow your data with less scrolling and searching.
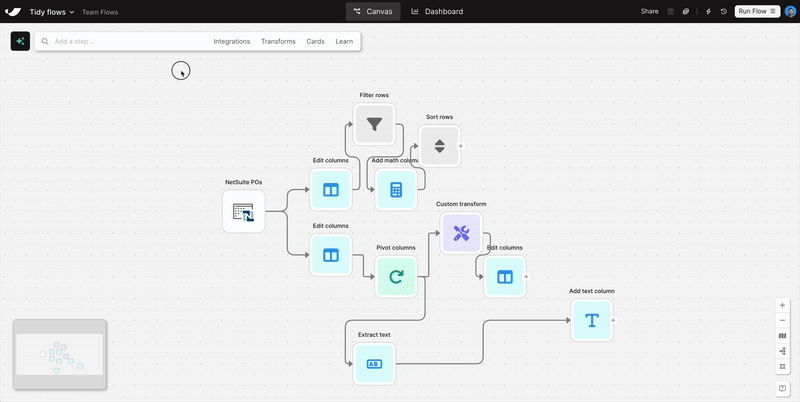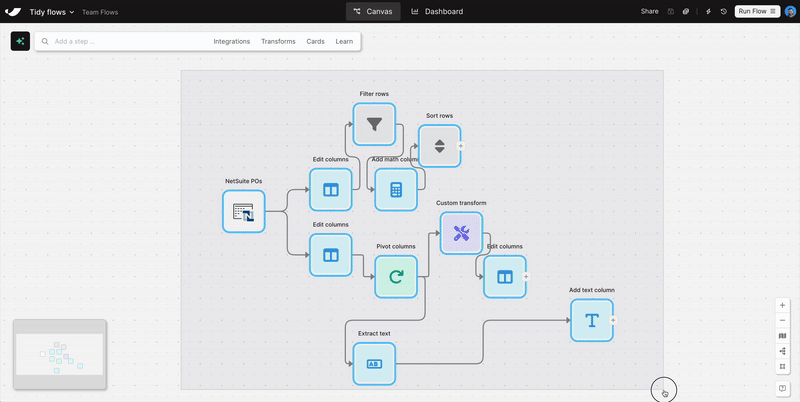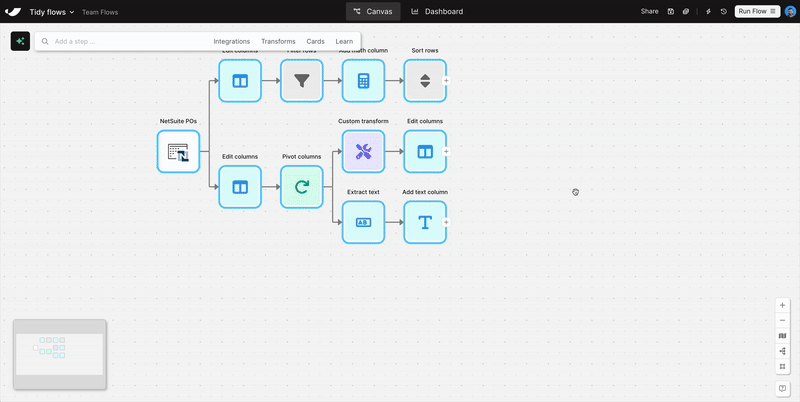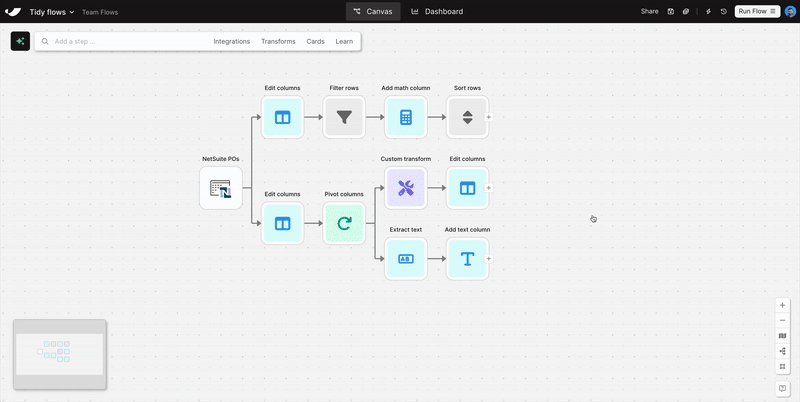
New
Tidy flows with a click
With the new auto-layout button, you can instantly organize your flow—making it easier to manage and share with teammates.
Improvement
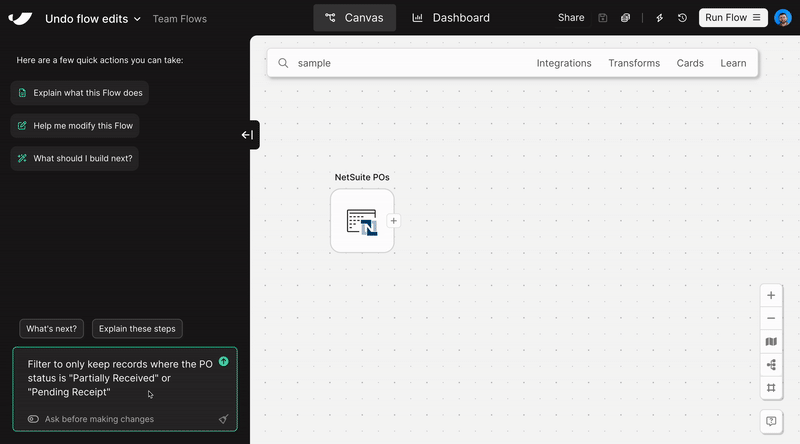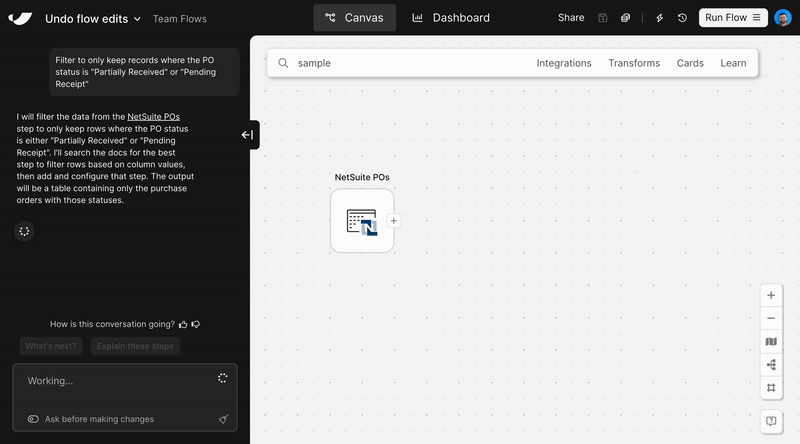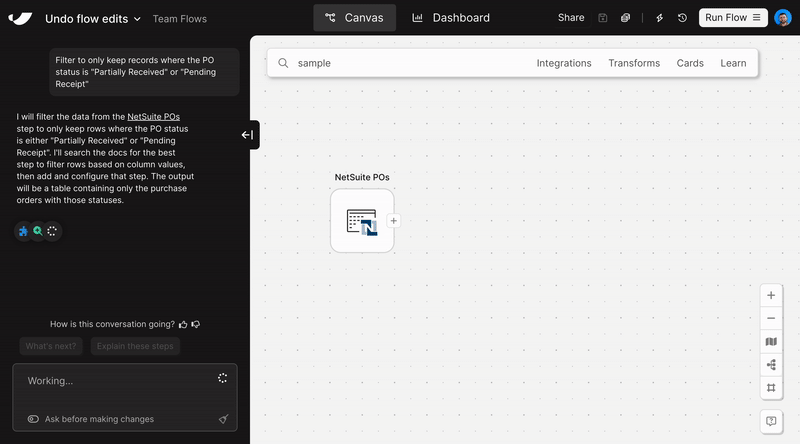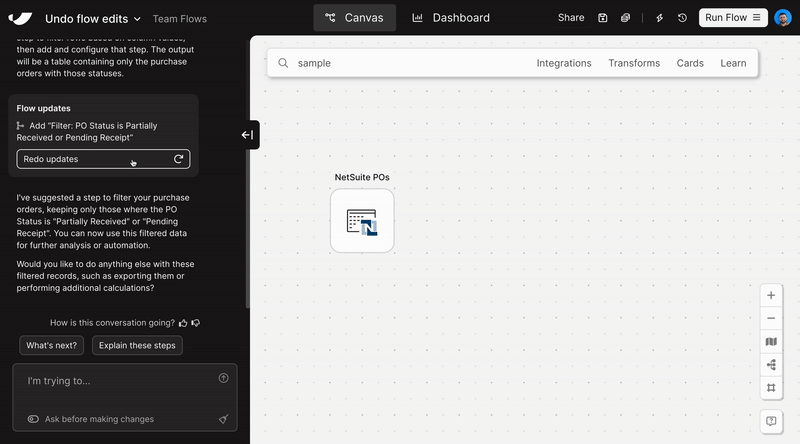
Vibe-automate flows with more control
Parabola makes real-time updates to your flows as you chat, often adding multiple steps after a single message. Build without fear using the new “Undo” button, available in chat after every flow update.
New
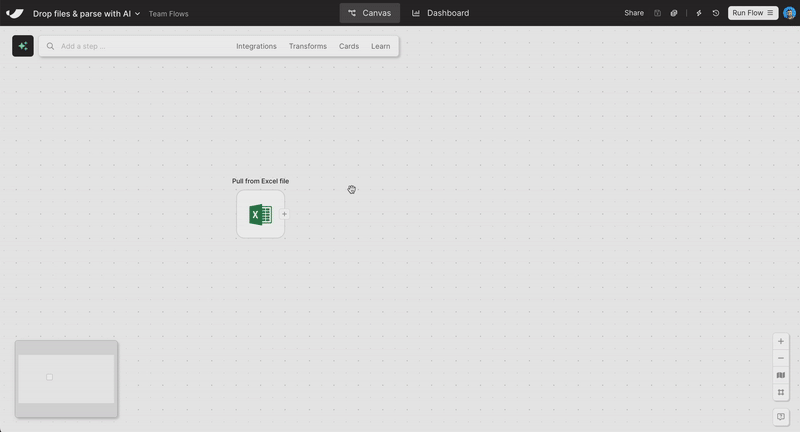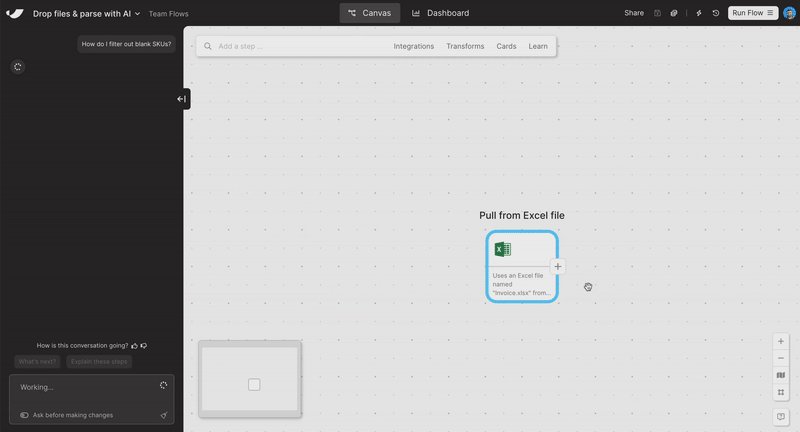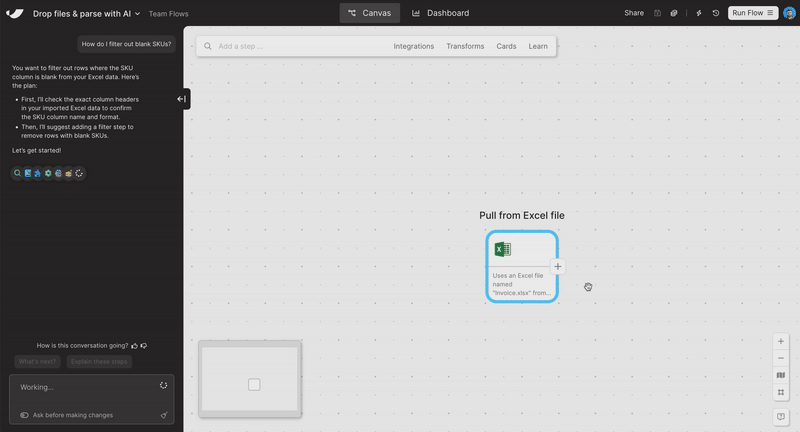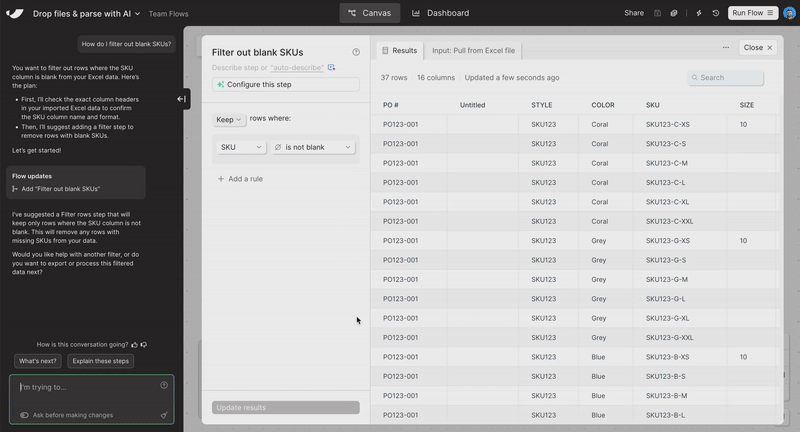
Clean and structure Excel files with AI
Turn messy spreadsheets into clean, structured tables. Try it out in the Extract from email step or when uploading an Excel file.
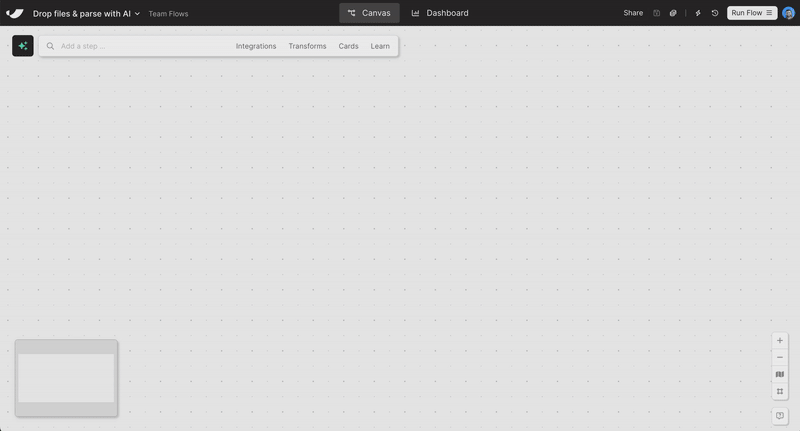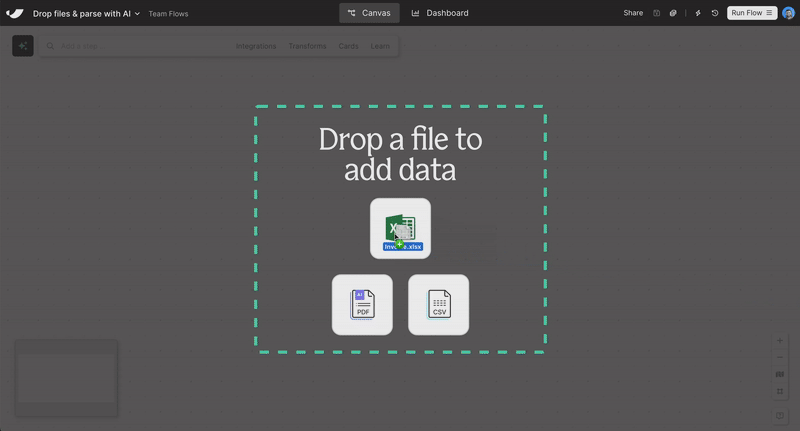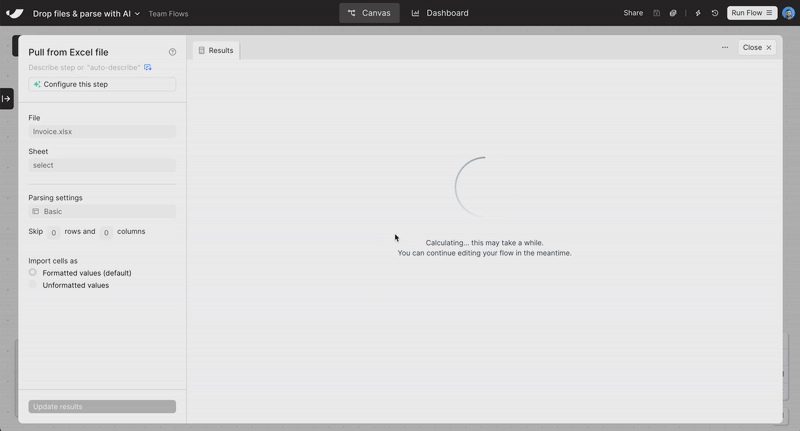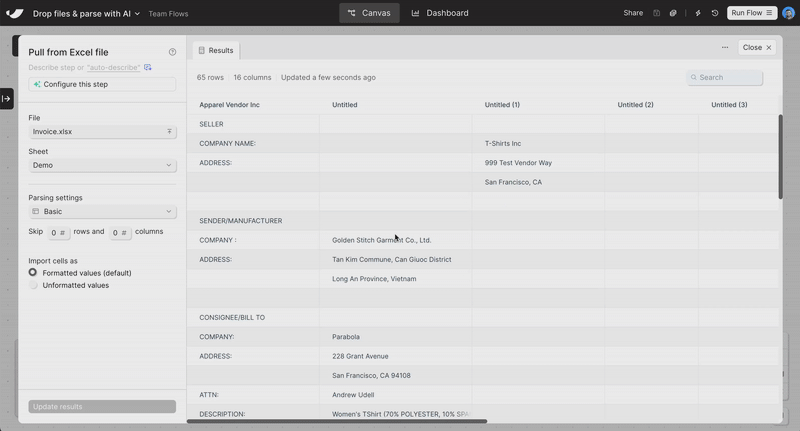
New
Drag-and-drop file upload
Skip the “Pull from” steps. Just drag a file onto the canvas—Excel, PDF, CSV, or JSON—and your data’s ready to go.
Improvement
Smoother chat experience
We’ve made a few improvements to make our new AI chat interface feel easier to use. Plus, send messages directly from the canvas and use the shortcut [ to open and close the sidebar.
New
New team usage reports
“Which Flows use our Snowflake credentials? Who has access to those Flows? How many of those Flows have run in the last 30 days?”
Admins: answer all these questions—and more—using the new “Usage reports” on the billing page. Contact your account manager for more information (available on Advanced plans only).

New
Welcome to the new Parabola
Today, we're introducing a completely new way to build in Parabola. It’s the clearest expression of what we’ve always set out to build.
At its core is a new AI-powered chat interface that makes building, troubleshooting, and documenting Flows feel conversational. Simply type what you want to automate, and watch it come to life.
Try it now and watch your ideas turn into outcomes 100x faster. We can’t wait to hear what you think.
.gif)
New
Flow faster with the quick-action toolbar
It’s easy to get into a “flow state” while building in Parabola—pun intended.
The more you build, the easier it gets to mentally map out your next few steps. With our latest update, we’re slashing the amount of time it takes to go from knowing what you want to build and actually getting those steps on the canvas.
Next time you’re in Parabola, search for steps and keywords directly on the canvas to quickly map out the structure of your Flow and bring your ideas to life, faster.

New
Create custom transform steps (!!!) with AI
We just released our most powerful AI step to date—making it 10x easier and faster to build Flows in Parabola.
With our new Custom transform step, you can create your own custom Parabola transformation steps by simply typing out instructions using plain language. The days of stringing together dozens of steps to work through complex logic are over—and in its place, we’re introducing our most flexible step ever.
🎁 Interested in trying out the step with a chance to win $250 or Parabola swag? To celebrate this launch, we’re running a contest through next Friday (4/11) to see the creative ways our customers solve complex problems with this step.
To learn more about the contest, see a demo, and explore potential use cases, check out our product launch doc. We think you’re going to love it…excited to hear your feedback!
Improvement
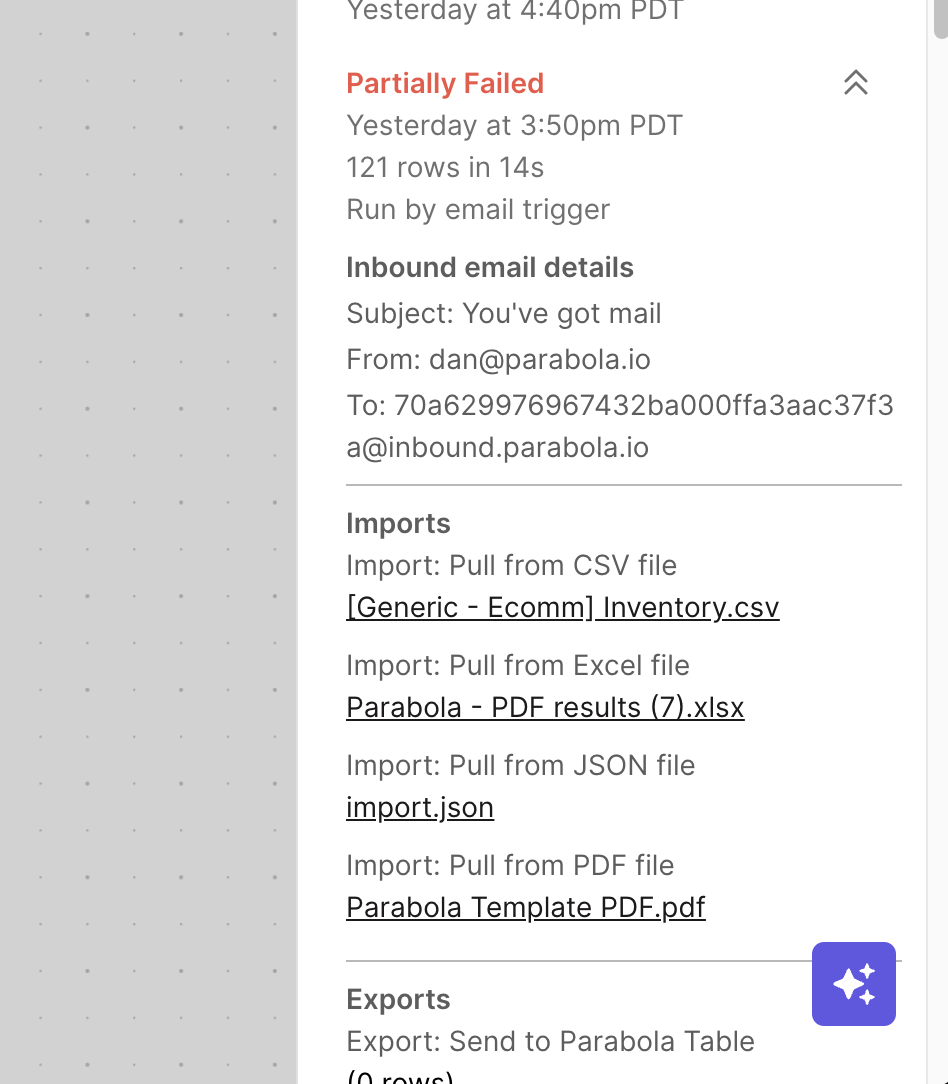
Understand what data flows through your Flows
Building on our recent update to show all previous Flow runs, we're adding even more context to each Flow run.
Your Flow run history panel now displays details about any email or webhook sent to the Flow, along with downloadable links for any files ingested into the Flow.
You'll always know exactly which email and file were associated with each run.
We've also reorganized the logs for better readability. These improvements are reflected in Flow run summary emails as well.
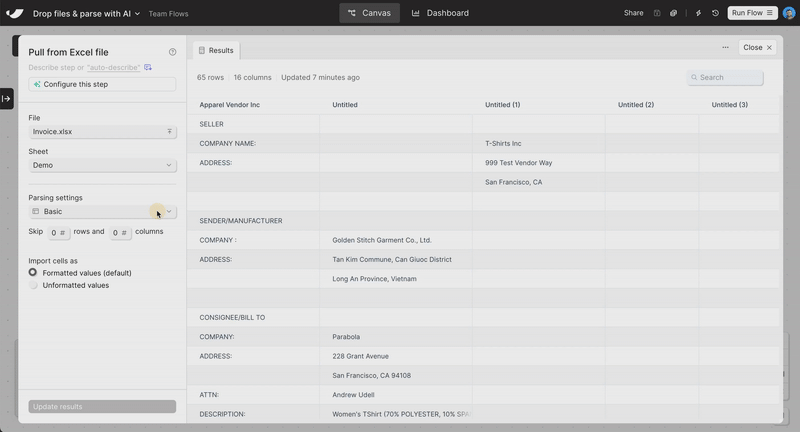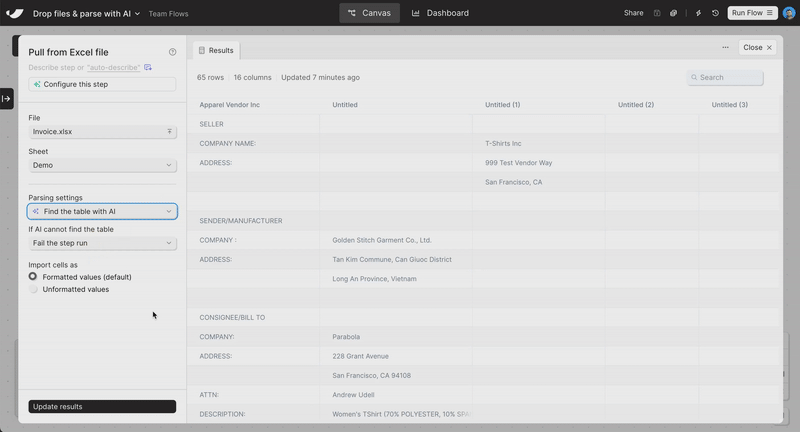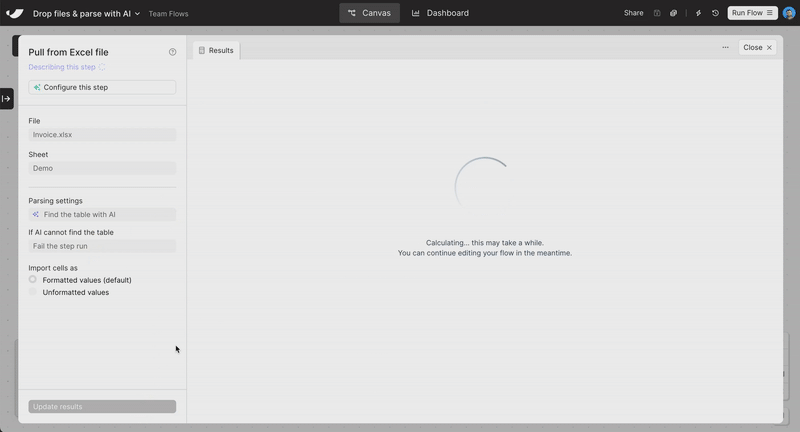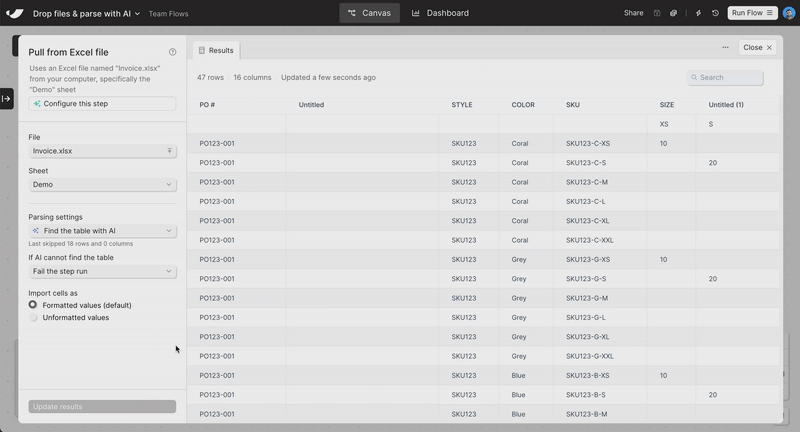
New
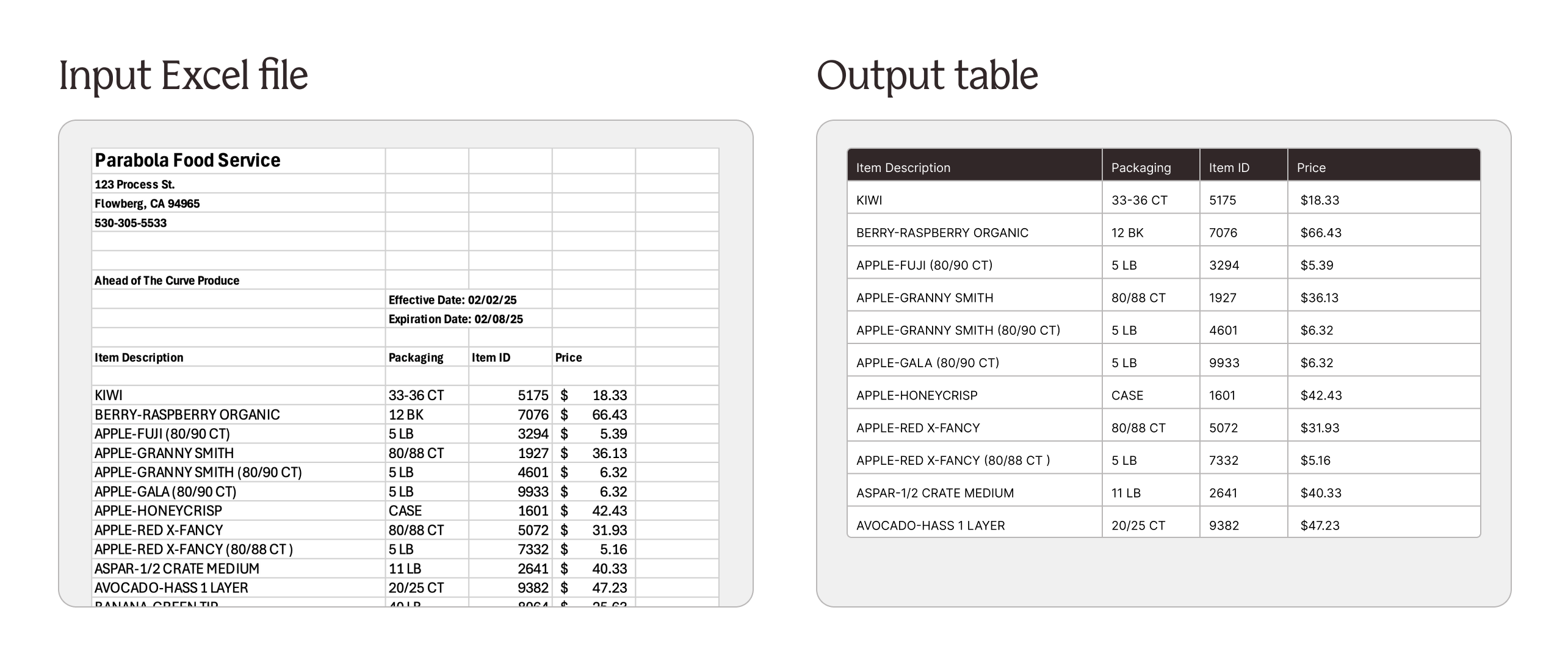
Parse simple tables from spreadsheets with AI
Working with files like Excel, CSV, or Google Sheets often means working with formats that change over time. The table you need might start on the 10th row in this file, and the 15th row in that file. This can make building Flows difficult and brittle.
With the new “Find table with AI” option, you can use AI to automatically find the table in your spreadsheet — allowing fast and flexible parsing of Excel files, CSVs, and Google Sheets.
Use this option in our Pull from Inbound Email, Excel, CSV, File Queue, and Google Drive steps.
New
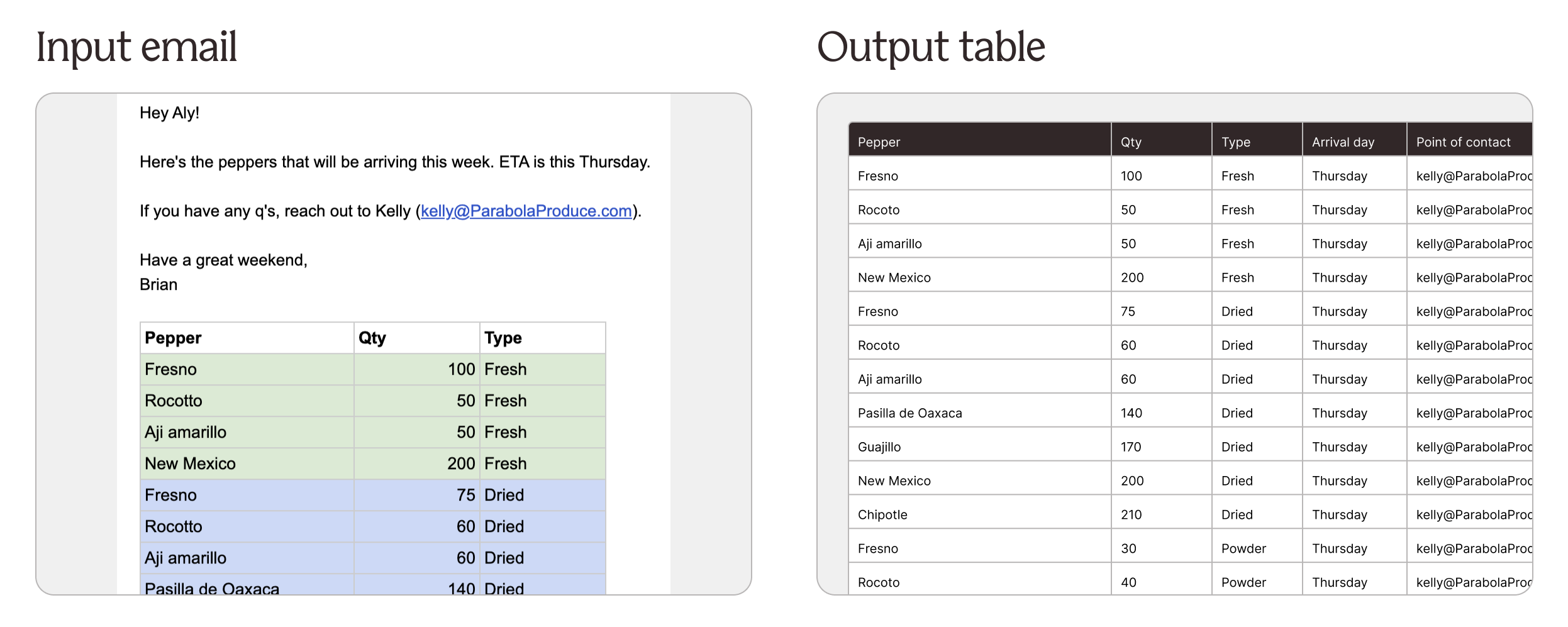
Extract data from email bodies using AI
Emails are a primary communication channel for business critical information. Staying on top of the latest replies and syncing information from emails into other systems is tedious and manual.
With the new “Extract data with AI” option, you can use AI to automatically extract tables and key values from email bodies to create structured output.
Find this option in the “Pull from inbound email” step when pulling in the “Email content”.
Improvement
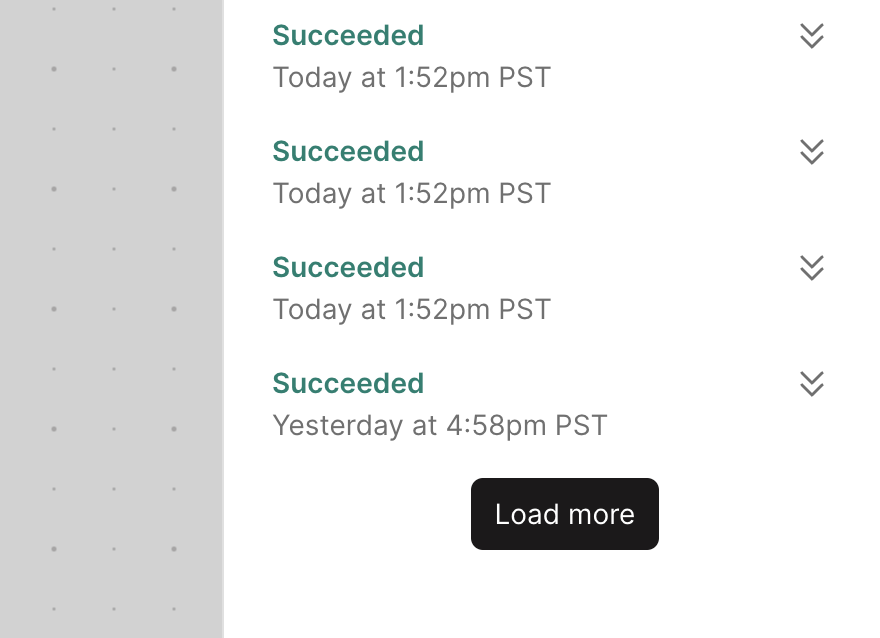
View all previous Flow runs
A small yet useful update has been shipped to the Flow run history panel.
Use the "Load more" button to go back further in time to see every run that a Flow has performed. Each click loads an additional 20 previous runs.
Improvement
Improved Extract, Categorize, and Standardize with AI steps
Hundreds of Parabola customers use AI to make sense of unstructured data and build powerful, streamlined Flows.
AI steps in Parabola are now not only faster to set up and run, but also deliver more accurate results. The recent upgrade includes three major highlights:
- A new testing experience: A fast feedback loop is key to successfully configuring AI steps. You’ll now see the ability to test your settings on a certain number of rows, directly inside of any AI step (just click the ⚙️ icon).
- Speed and scale improvements: AI steps now run 2x faster allowing them to support larger amounts of data.
- Enhanced prompting for Extract and Categorize: Similar to our PDF parser, our Extract and Categorize steps now allow you to provide example values and column-specific instructions to improve the accuracy of your results.
From your messiest documents to your tidiest ERP reports, leverage these improvements to extract, categorize, and standardize data with the power of AI.
Improvement
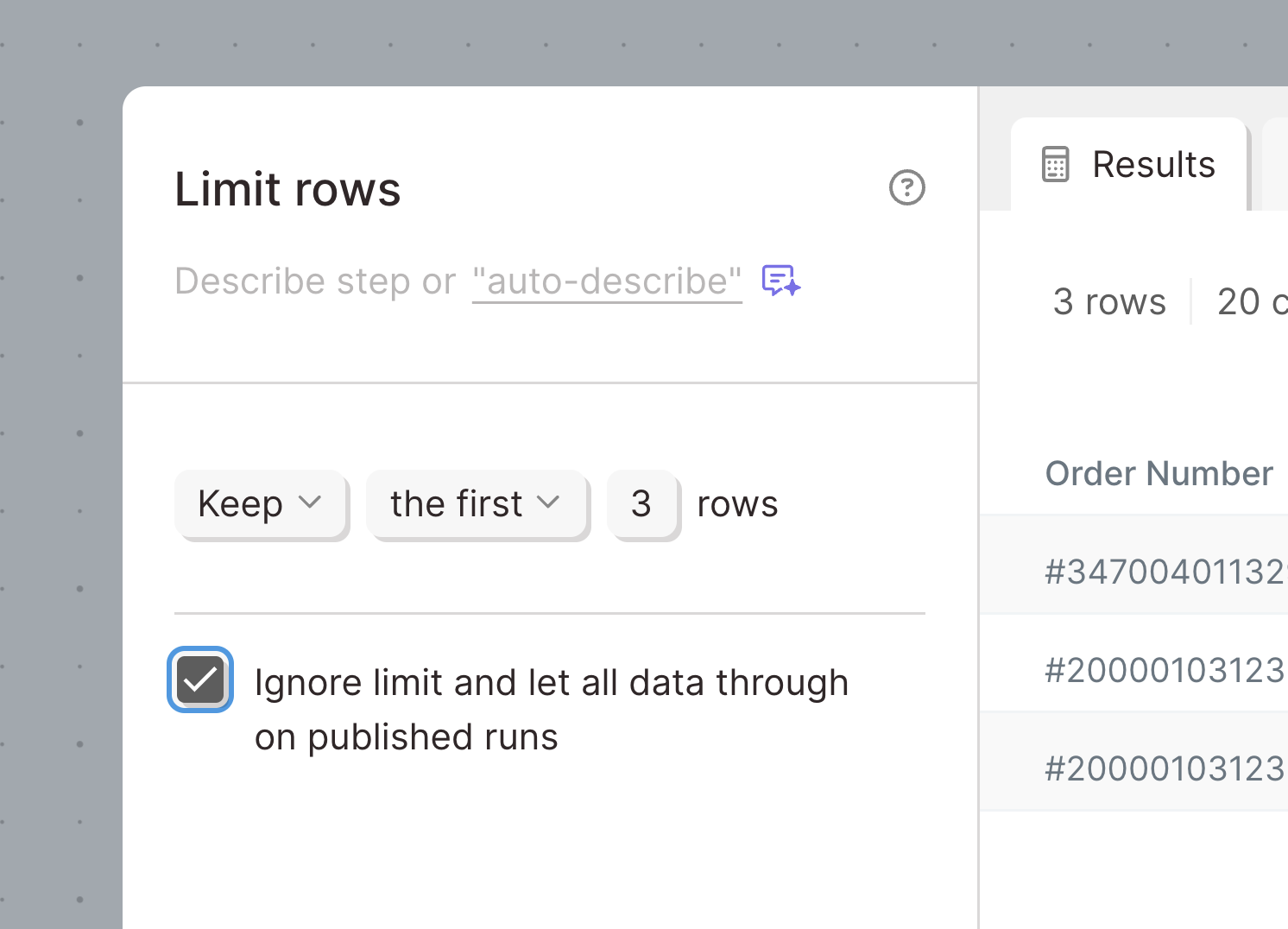
Limit rows while you build
When building in Parabola, there are times when you want to process some data, but not necessarily the entire dataset — like when you’re setting up an API call, joining large datasets, or using an AI transform.
With the latest upgrade to the "Limit rows" step, you can choose to limit your dataset just while you build — but remove the limit and use the entire dataset when the Flow actually runs. That means no more waiting on thousands of API calls or a complex "Find overlap" step while you build.
Check it out and let us know what you think!
Improvement
Pull in custom fields from NetSuite
The Pull from NetSuite step has been updated to pull in custom fields and display them in the same way they appear in your saved searches. Prior versions of the step could pull in some custom field data, but it was difficult to use in a Flow.
Now, custom fields will appear as additional columns along with any other supporting data returned by NetSuite.
New
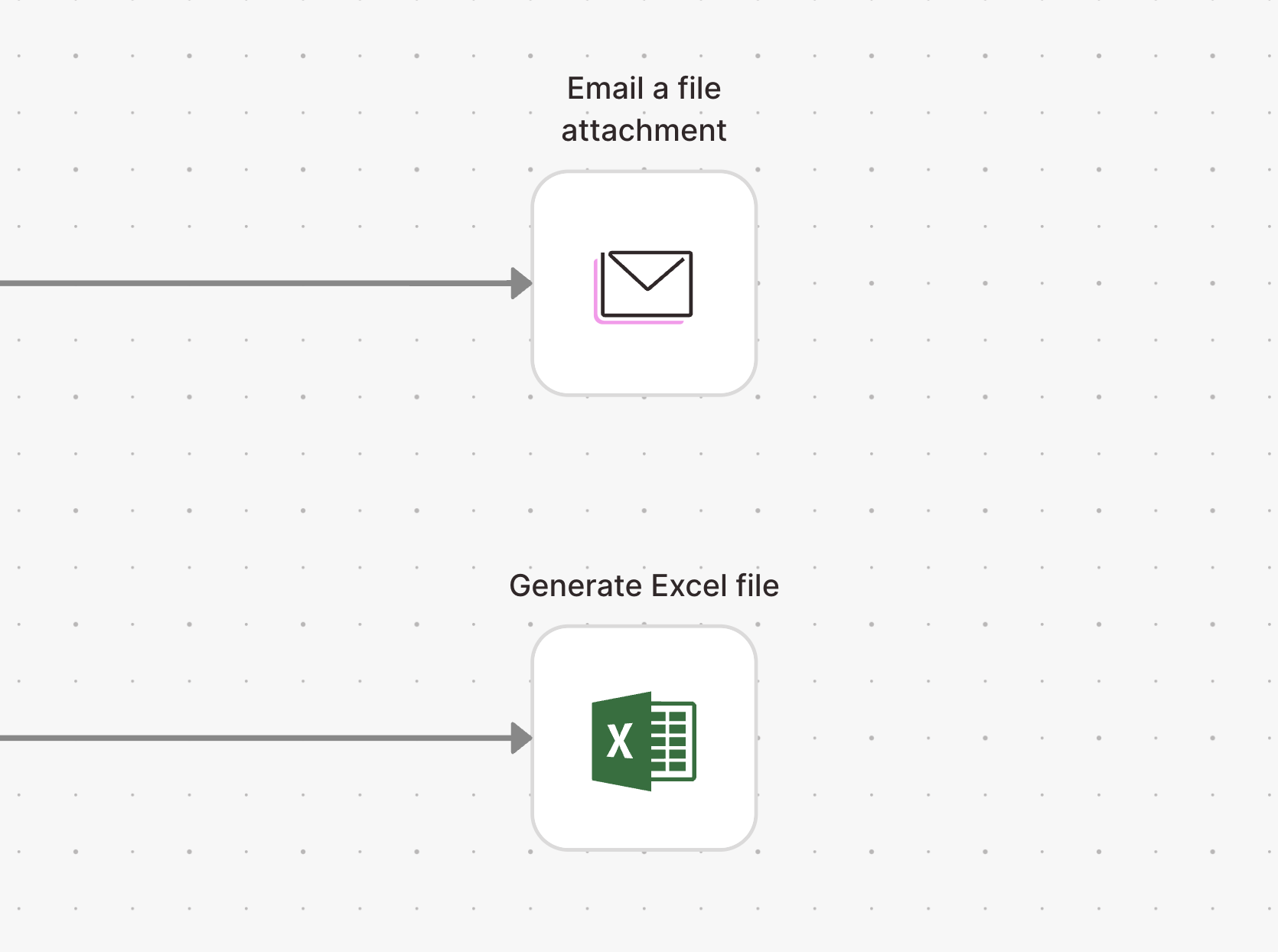
Email and download Excel files
Flows are now more flexible with the addition of Excel file exports.
- Use the Email a file attachment to automatically email Excel files
- Use the Generate Excel file step to create downloadable Excel files
Both steps support multiple input arrows to create multi-sheet workbooks.
Improvement
📣 Saving, sharing, and managing accounts just got a whole lot easier
We’re excited to share a major upgrade to the way you and your team manage integrations in Parabola 🎉
With this release, you’ll have the ability to save and share integration accounts across your organization – making it easier for you to…
- Manage and re-authenticate accounts (if an authentication expires, you only need to update it in one place, and all Flows using that account will be updated)
- Improve visibility into integration accounts across your organization
- Share integration accounts across your team
- Manage permissions for specific accounts
For a brief overview of the upgrade, check out this quick video, and explore our announcement doc for more information and optional migration details. We think you'll really enjoy the new system!
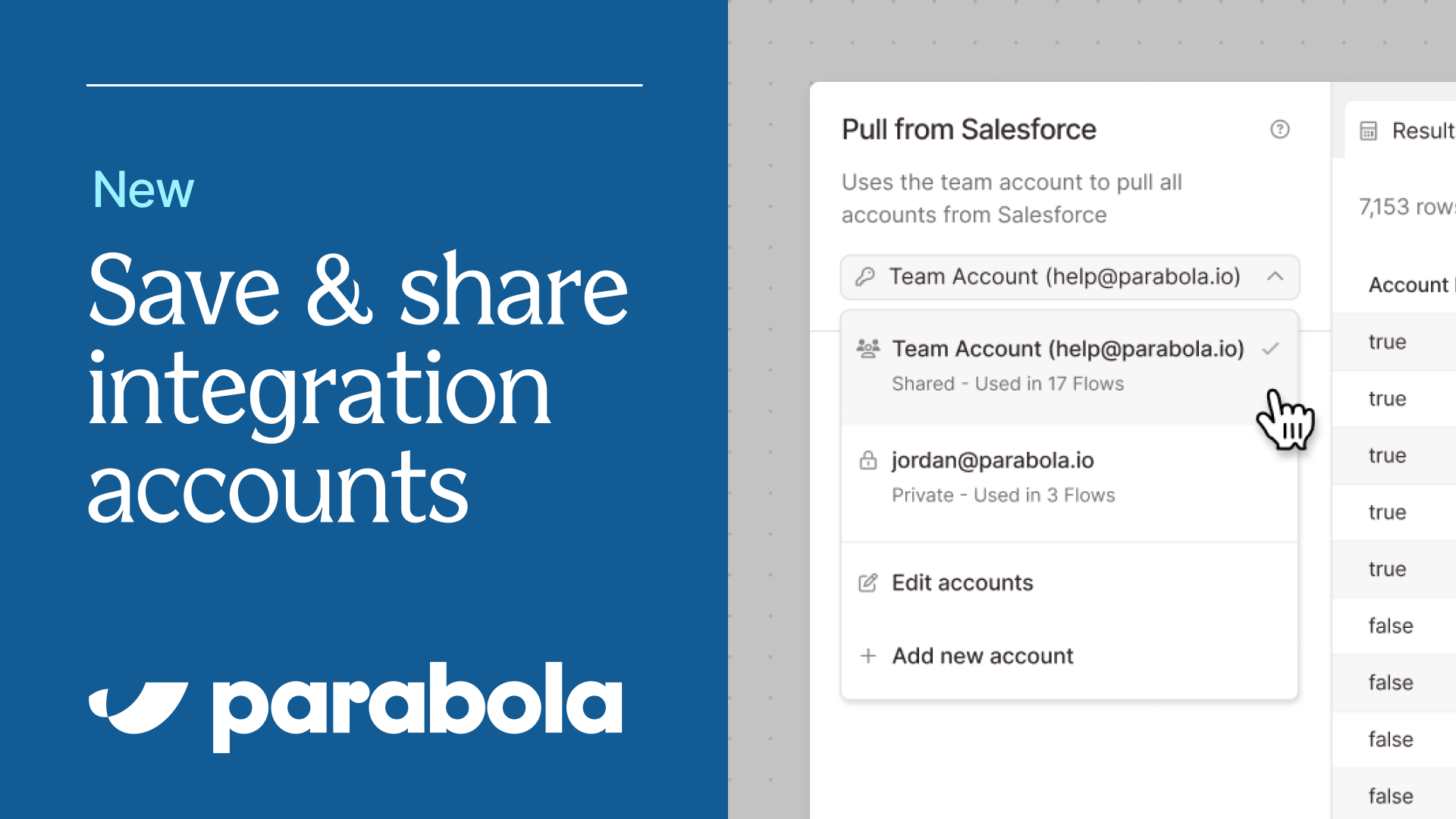
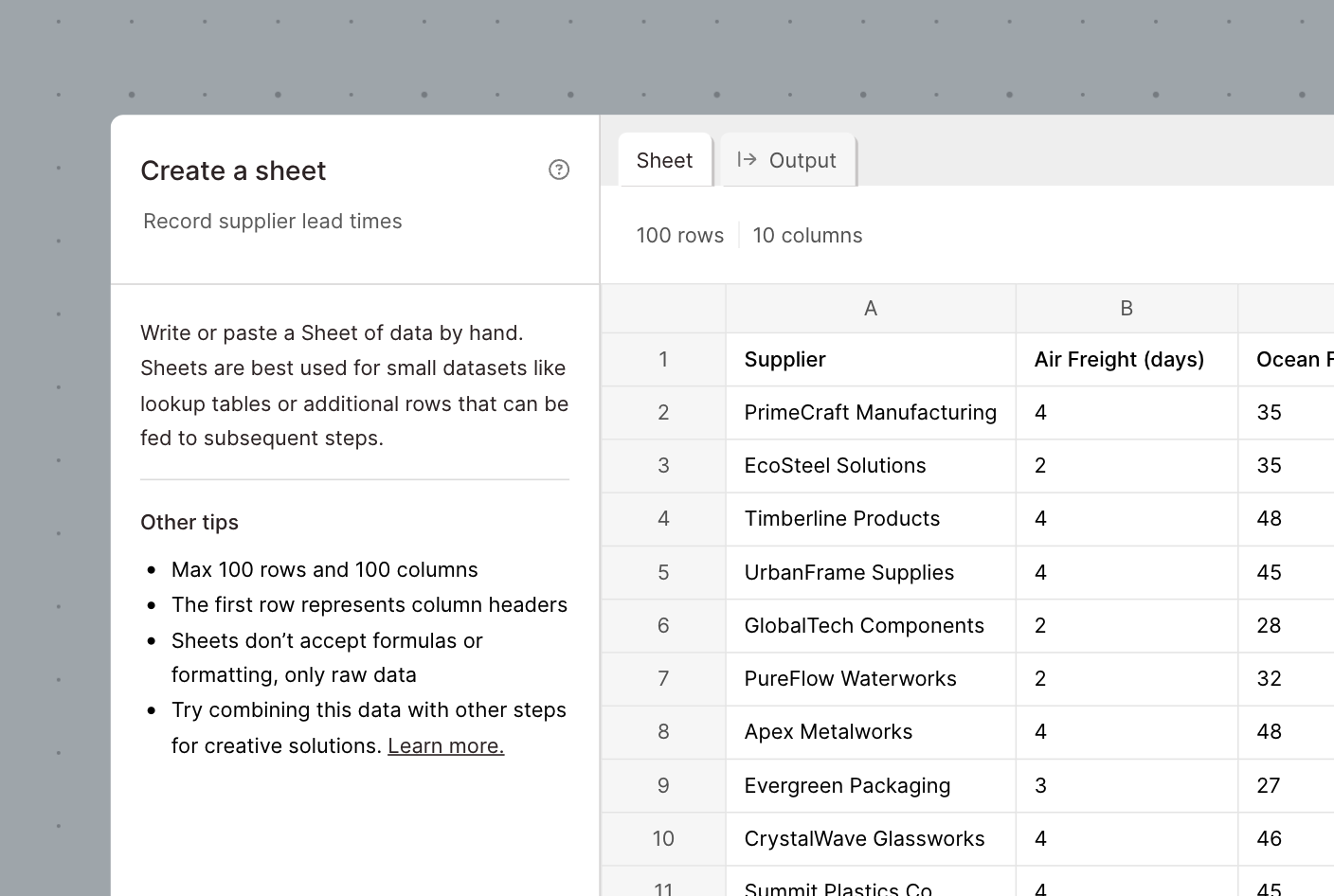
New
Create, save, and update spreadsheets in Parabola
If you've ever used Parabola, you've probably wanted to edit specific cells of data or 'just create a reference table' more than once while building.
With the new "Create a sheet" step, you can write or paste data directly into a spreadsheet interface and use that data throughout your Flow. This is particularly useful for situations where you want to create a dynamic reference table, test different scenarios/variables, and want to cut out working across Google Sheets and Parabola.
Check out the "Create a sheet" source step and our How To documentation to learn more!
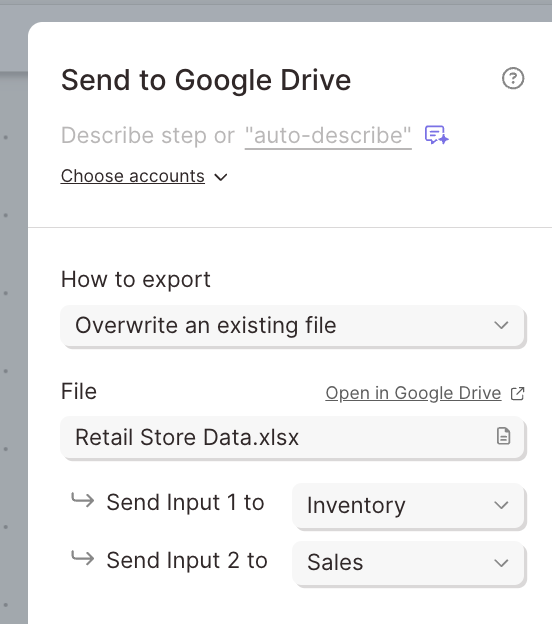
New
Create Excel and CSV files in Google Drive
To further Parabola's integration with the Google ecosystem, we're excited to release a new Send to Google Drive step which supports...
- Creating Excel files with multiple tabs
- Creating CSV files
- Creating and updating Google Sheet files
This step will live alongside our existing Send to Google Sheets step to provide flexibility as you build. Check out the details in our product documentation and reach out with any questions!

New
Visualizations on the canvas, dynamic dashboarding, and live Flow editing with more powerful drafts
Three major updates in one 📊 here’s a breakdown of the release:
- Visualizations on the canvas: You can now drop dynamic visualizations (like charts, graphs, and tables) directly on the canvas to see reports update in real-time as you build.
- Dynamic dashboarding capabilities: It’s now even easier to graduate from Spreadsheet Land and create BI-quality dashboards with a faster feedback loop.
- Live editing & powerful drafts: You can now edit Flows in real-time without needing to create drafts for every change — just directly edit the live version of your Flows, and watch updates automatically save.
Check out the video below for a full overview of the new functionality — and to see these features in action, explore this collection of free demo Flows. Happy building!
New
AI-generated process documentation for your Parabola Flows
We’re excited to share that Parabola Flow documentation is getting a major boost 📝
Parabola Flows now use AI to analyze every step in a Flow, automatically adding process documentation as you build. Gone are the days of writing out a detailed SOP only for your process to change the next day!
Next time you build in Parabola, you’ll see that the new “documentation” section of every Step will be automatically updated as you build.
Learn more about the details in this blog post.

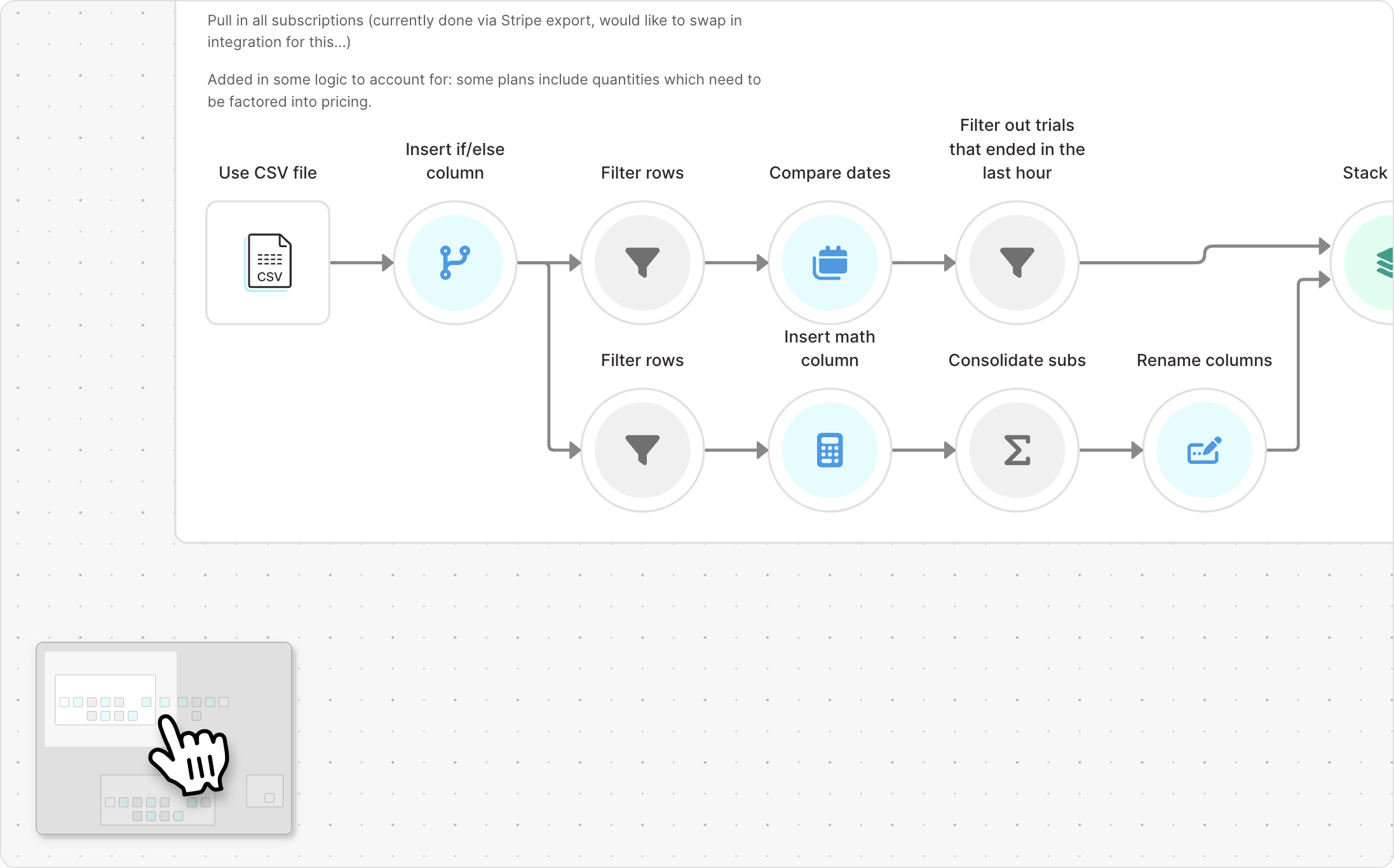
New
Navigate complex flows with our new mini-map
We're excited to introduce the mini-map, a new feature designed to help you navigate large and complex flows with ease. The mini-map provides a compact, interactive overview of your entire Parabola flow, allowing you to quickly orient yourself and move between different sections of your workflow.
You can toggle the mini-map on or off using the map icon in the zoom toolbar.
Improvement
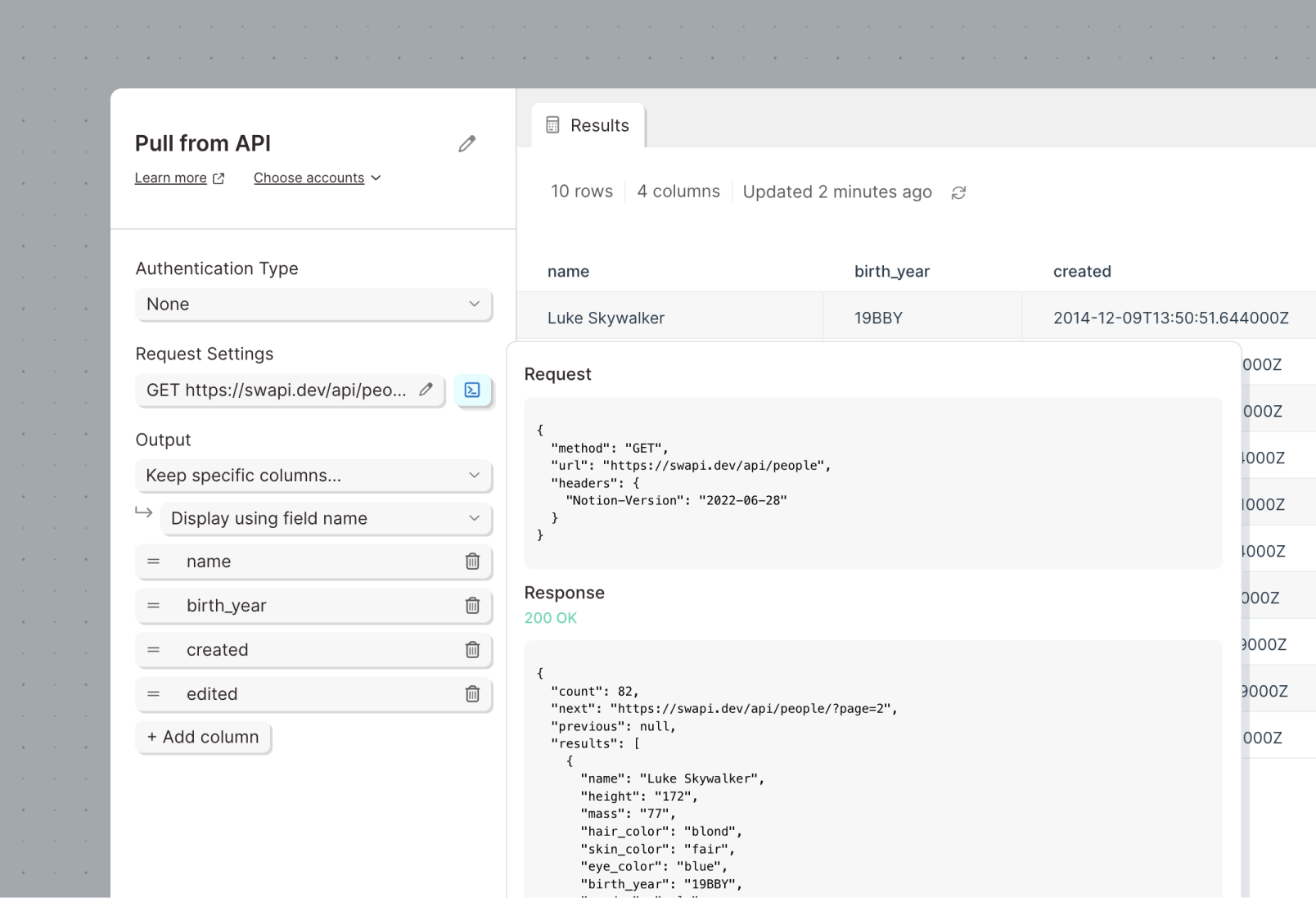
An easier and more powerful way to connect to APIs
Connecting to APIs in Parabola is easier than ever: The Pull from API, Enrich with API, and Send to API steps have been redesigned to make configuration and testing a breeze.
- Connection settings all in one place: Our redesigned connection panel gives you more space when you need it, and no worry when you don’t.
- View the request and response: Use new controls to view the full request and response data sent between Parabola and the API for faster testing and iteration.
- Just point and click: With the new output settings, keep the columns you need from the API, and forget the rest.


Improvement
Parse multiple PDF formats with AI using a single step
We’re excited to announce a new feature in our PDF AI parser that allows you to parse multiple formats of PDFs with greater control and precision - all in one “Pull from email attachment” step!
You can now set specific rules (called “formats”) for different types of PDFs that you receive via email, using a new mode that lets you configure multiple PDF formats — for example, invoices from different vendors — and pull key pieces of information from each.
To route PDFs to specific formats, you can create rules based on the file name, subject line, or other email metadata.
.png)
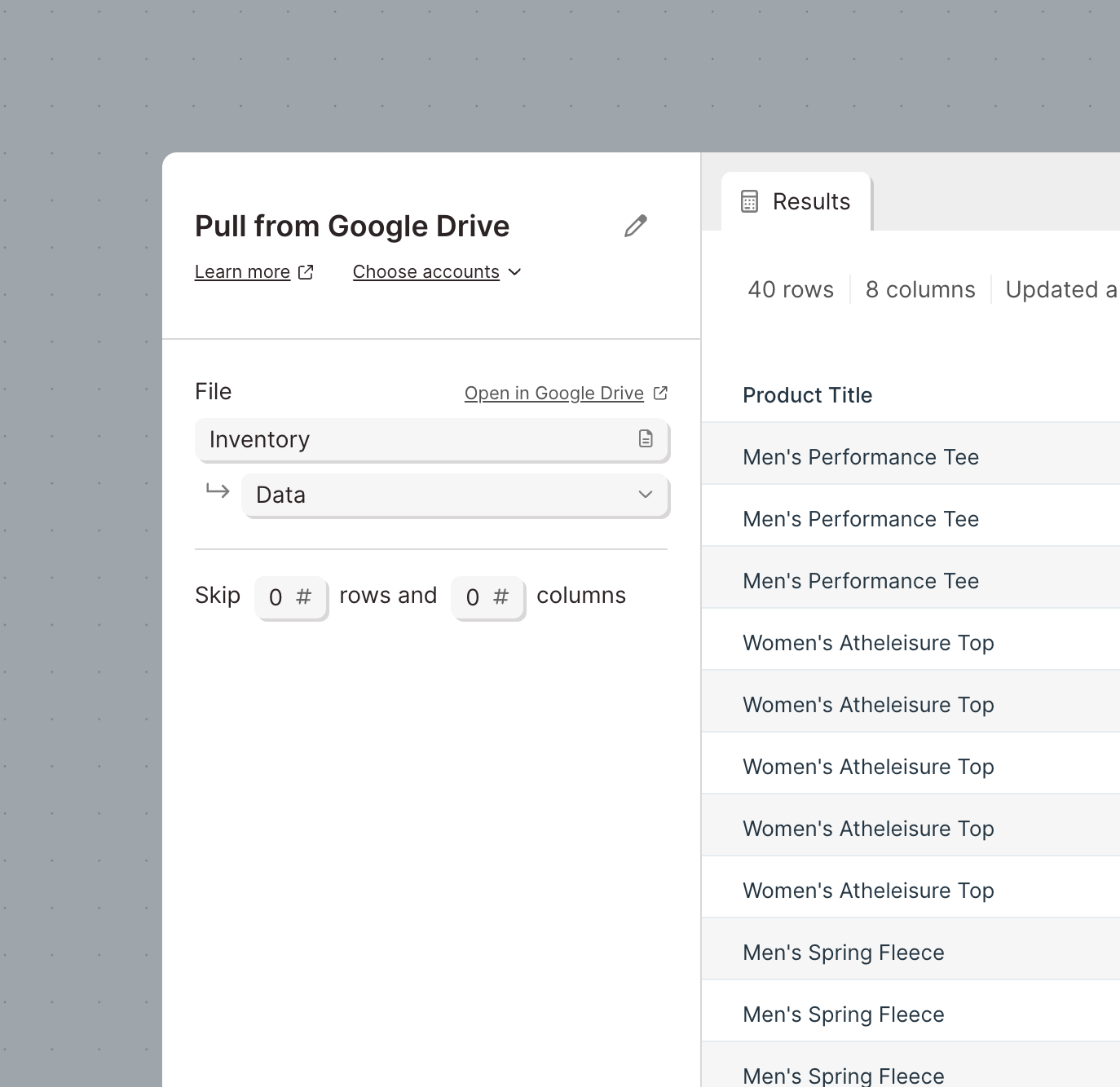
Improvement
Pull in Google Sheets, CSV, and Excel files from Google Drive
Our Pull from Google Sheets step has been upgraded to pull more types of files from Google Drive. In addition to accessing Google Sheets, this step can be used to pull in CSV and Excel files stored in your Google Drive.

Improvement
Pull URLs from emails
We’ve updated the Pull from inbound email step with options to pull in the full HTML representation of the body of an email, as well as a parsed list of URLs contained within the body.
This list of URLs can be used to isolate URLs from an email, fetch a document from that URL, and then process that document via the Pull from file queue step.

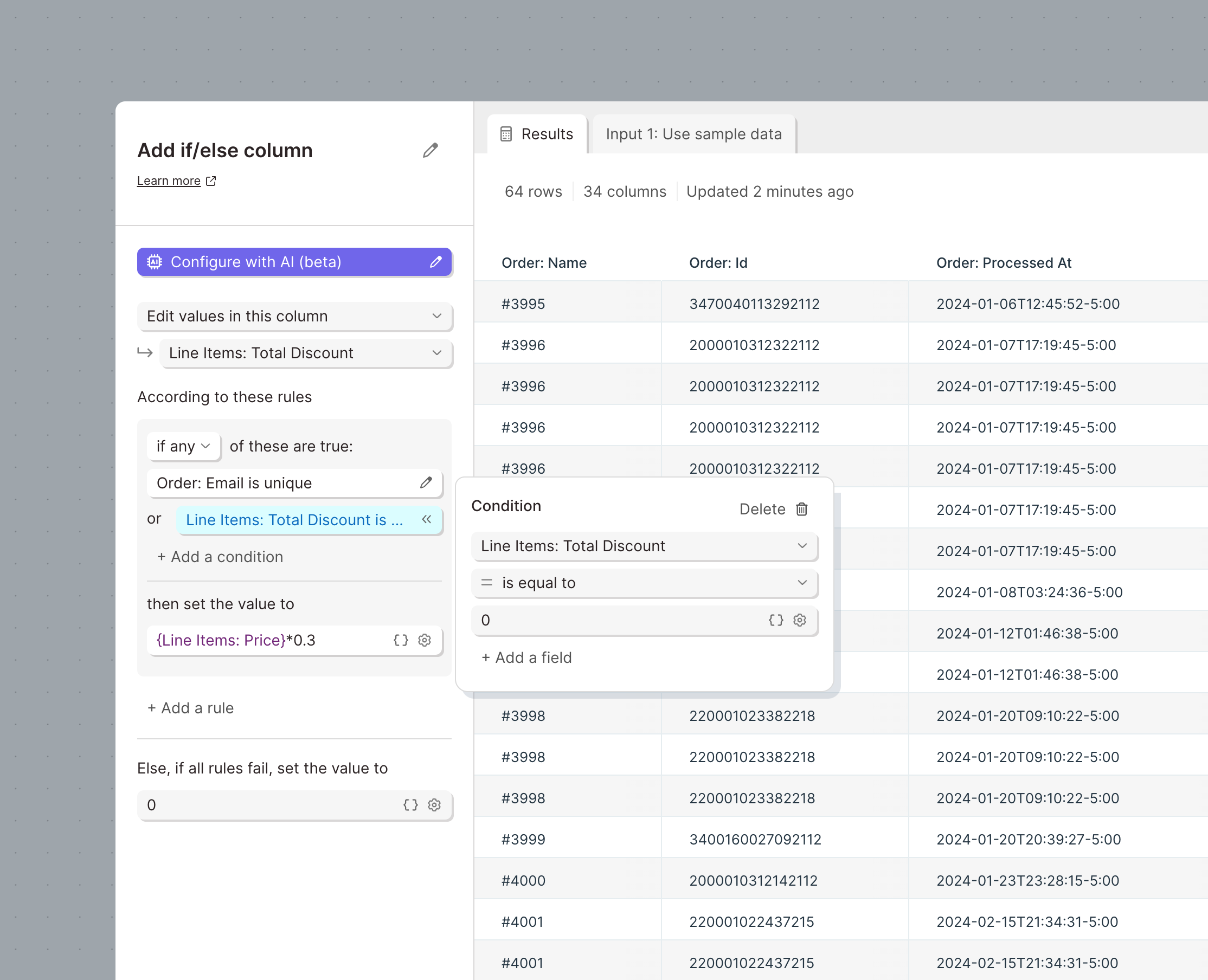
Improvement
Huge updates to the Filter rows and Add if else column steps
Filtering rows and if else logic are at the heart of every Parabola Flow. We’ve given both steps a massive upgrade to make them faster, easier to use, and more powerful
Both steps have access to series of new operations:
- Filter dates to… (filter dates relative to now or a set date)
- Is unique (is the value in each row unique within that column)
- is not unique (is the value in each row not unique within that column)
- Text is equal to (equals but assumes text - faster than “is equal to”)
- Text is not equal to (equals but assumes text - faster than “is not equal to”)
- Text starts with (matches the first part of a cell)
- Text ends with (matches the last part of a cell)
- Text length is (length of cell = #)
- Text length is greater than (length of cell > #)
- Text length is less than (length of cell < #)
- Text matches pattern (regex match)
- Text does not match pattern (inverted regex match)
- Is between (between two numbers)
- Is not between (not between two numbers)
Text field level options - accessible via the settings cog icon on the right side of any text field:
- Each text field can be toggled to evaluate what has typed in as a math expression, instead of just text. You can type numbers or reference them from columns using {merge tags}
- Each text field can be toggled to match based on the casing provided, or ignore the casing of the text
Add If else column step-specific updates:
- Choose to replace value in an existing column, as opposed to only create values in a new column
- Add additional criteria to a single condition. This was already supported in the Filter rows step. For example, define a list of items that a field may be equal to.
- To accommodate all of these amazing features, the Add if else column step has a new design that is more compact and easier to read
Improvement
Updates to email trigger Flow failures
Parabola Flows can be set up to be triggered to run via an email. When an email is sent to a Parabola Flow, the Flow will try to enqueue the new run. If that enqueueing fails, an email is sent back to editors of the Flow alerting them that a certain email could not be processed.
With this change, that email also:
- Contains the name of the file attached that caused the issue (such as the wrong file type)
- Sends to the email address who sent the original email in to Parabola
Improvement
New options to run Flows from other Flows
Use the updated options in the Run another Parabola Flow to run Flows in sequence. The new options are:
- Run once per row
- Run once per row with a file URL
If Flow 1 tells Flow 2 to run, these options will allow Flow 1 to finish running before Flow 2 has finished. In the existing options, Run once and wait, and Run once per row and wait, the step will wait for Flow 2 to finish before it can finish.
Using the Run once per row with a file URL option will add runs to the file queue of Flow 2.
.png)
New
Pull files into Parabola from URLs
Use the new Pull from file queue source step to access and parse files at the end of URLs.
The file queue works like a webhook or email trigger, but can be triggered via an API call (webhook) or the Run another Parabola Flow step.
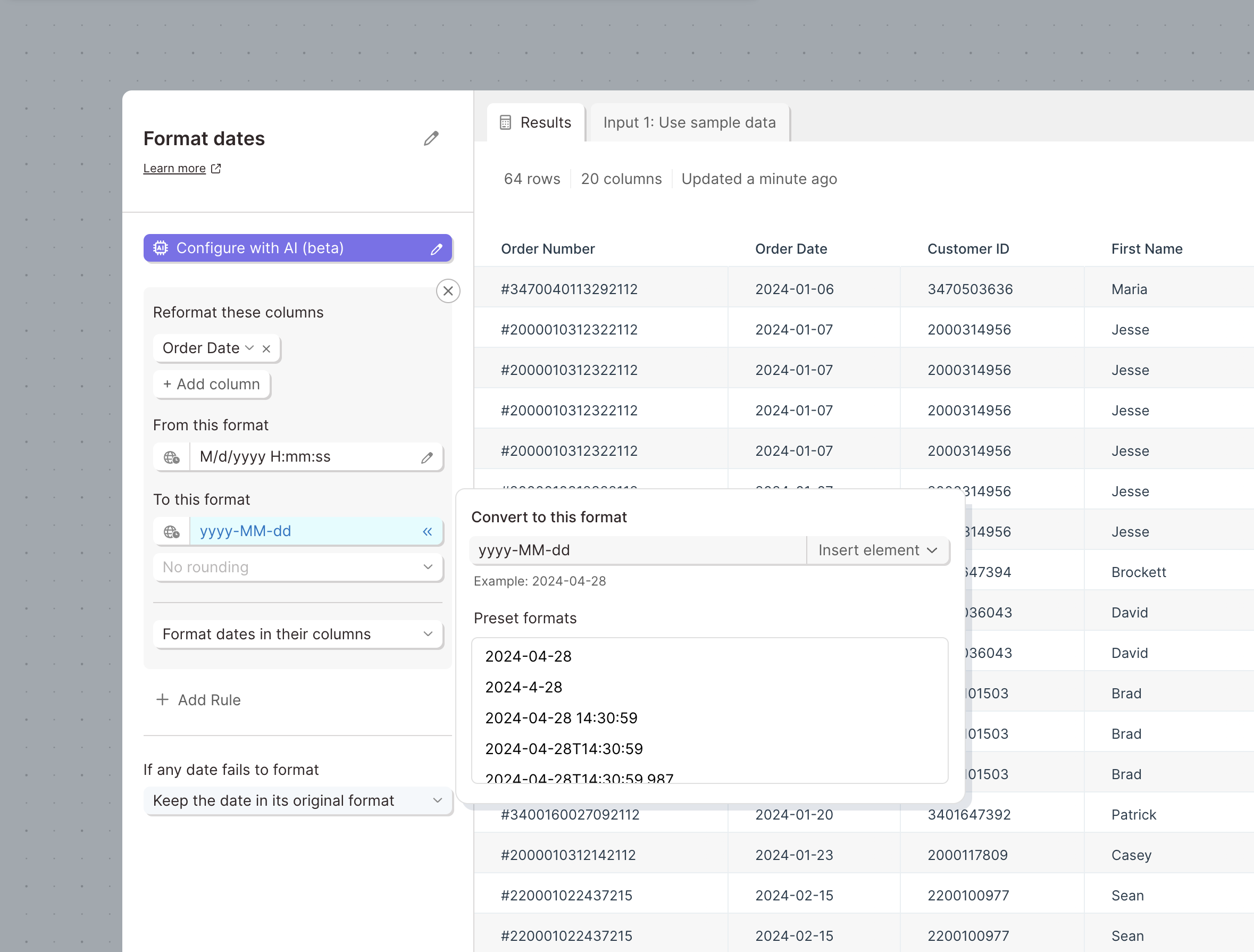
Improvement
Work with dates in an easier, more powerful way
Use the updated Format dates step to easily change the format of dates, convert between timezones, round dates, and more.
This update completely overhauls the step with a new powerful date engine, updated interactions and design, and AI auto-detection.
We've added support for converting between timezones and precisely rounding dates.
New
Configure steps using the AI co-builder
Introducing, the AI co-builder. Configure steps quickly and easily using AI to transform simple prompts into complex rules and settings.
To use the AI co-builder:
- Click the “Configure with AI” button to access the co-builder.
- Enter instructions for how to configure the step and click “Configure it for me”
- Once the AI has determined the right configuration, any existing settings will be replaced with the new settings.
The AI co-builder only runs when you click to configure the step. During subsequent runs, the step will not use AI to create results.
Now available in limited steps during the beta:
- Replace with regex
- Filter rows
- Format dates
- Find & replace
- Add if / else column

New
Introducing Parabola University: Learn, Build, and Grow
We're thrilled to launch Parabola University, a dedicated space on our website featuring video tutorials that guide you through creating effective Flows. What's more, you can access these helpful videos directly from the menu bar while you're building Flows.
Improvement
New Look, Refreshed Experience: Welcome to Our Rebrand
Our website and product interface have undergone a stunning transformation! Explore the new colors, styles, and overall look and feel that reflect our commitment to making your experience more vibrant and user-friendly. It’s not just a makeover; it’s an upgrade to how you interact with Parabola.

Improvement
Colorful, collapsible cards and streamlined navigation
We've released a few new features to make sharing and getting around Flows easier.
🎨 Colorful, Collapsible Cards: Dive into our latest update where you can now compress parts of your Flow with collapsible cards and organize them with vibrant, colorful banners. It's easier than ever to manage and share your workflow.
🧹 Simplified Flow Navigation: Alongside, we’ve refined the navigation to smoothly toggle between Published and Draft versions of your Flow, ensuring a cleaner and more intuitive experience.

New
Access files sent to Parabola Flows with new URLs
The Pull from Email Attachment step now supports creating URLs to access the files that have been sent to a Flow.
When this option is enabled, the step can be configured to create URLs that are publicly accessible, accessible only to members of your Parabola team, or accessible to teammates who have access to the Flow.

Improvement
Send more types of API requests
More API request body formatting options
The "Protocol" dropdown in request body of all three API steps has been replaced with a "Format" dropdown.
In addition to JSON and GraphQL, Parabola now supports plain text, form-data, and x-www-form-urlencoded formatting types.
When using these options, if an API step does not already have a "Content-Type" header included, we will also now automatically add the right one, according to the last selection in the "Format" field.
This is available on all API steps - Pull from AP, Enrich with API, and Send to API

Merge tag support in header values
Utilize merge tags, columns referenced by name and wrapped in {curly braces}, within the value field of a custom header to merge in values for each API call from the input data.
Available in the Enrich with API and Send to API steps.

Improvement
Builder 2.0 is here!
We've completely overhauled the Flow builder to give you more performance, faster building, and more intuitive features.
Canvas
- Infinite canvas so you can build as far and wide as you’d like
- Better defined grid for improved spacing throughout your Flow
- Better performance for even your largest Flows
- Improved zoom and fit controls on the canvas
Steps and arrows
- Smoother arrow connection
- Updated design of step controls
Cards
- Place steps anywhere inside of cards
- Hold shift, click, and drag to multi-select steps inside of cards
- Move many steps in, out, and between cards
- Updated design of card controls

New
Integration with Microsoft SharePoint & OneDrive
Brand-new integration, hot off the press: we now support connecting to Microsoft SharePoint and OneDrive!
We want all teams to be able to access their data as easily as possible. With these new steps, you can access any XLS and CSV files in SharePoint or OneDrive. Pull your files into a Flow, create new files, or update existing files.
This integration is available to all customers. Please refer to our documentation for more details!

New
Introducing (really) Smart PDF Parsing with AI
Our latest release is next-level: it converts even your gnarliest PDFs into usable data, with really simple configuration.

Now combining two elements of AI—battle-tested OCR and cutting edge multi-modal LLMs—Parabola does all the hard work transcribing and importing your data for you, so there’s no setup required on your end.
Want to learn more about this new capability? Learn more
Improvement
We’ve made two big upgrades to our Google Sheets steps
1. The next time that you authenticate a Google Sheets step, you will see an updated experience. Instead of selecting files from a dropdown, you can use the native Google Drive file selector to find your file by searching or navigating through your Drive.
.png)
(Note: you will need to reauthorize existing Google Sheets steps in order to select a new file.)
2. When sending data to Google Sheets, you can now select a folder in which to create the new sheet(s), as opposed to always creating the file in the root of the drive.
We hope these upgrades make connecting to and using Google Sheets within Parabola easier and more delightful!
To take advantage of these changes, be sure to refresh your Flow.
Improvement
Email CSV Attachment step now supports dynamic content
By popular demand, our Email a CSV Attachment step now supports dynamic values. Values can be used in any field: the email subject, body, recipients, and even the file name of the attachment. Simply reference the desired column using merge tags {}, and the email will automatically insert the first row from that column. All the details here!
Improvement
Sequence Flows and share data between them
You can now connect the Send to Parabola Table step to any other step, and in particular, the Run another Flow step.
By connecting these two steps, a Flow can first send data to a Table and then run other Flows that pull data from that Table. This ensures that connected Flows run in the correct sequence and that data is passed directly between them.
.png)
Improvement
Pull multiple email attachments, and visibility into pending Flow runs
We’re delighted to announce that you can now process multiple attachments from a single email, using the “Pull from email attachment” step.
Previously, email-triggered Flows would always run with the first valid attachment received. Now, you can configure your Flow to run with each valid attachment received on a single email. So if you expect to receive one email with multiple CSVs, XLS, or PDF files, a single Flow can process them all, sequentially!
Check out all the details here.
We’ve also given you more visibility and control over your “queue” of pending Flow runs. For triggered Flows, you’ll see how many runs are pending, and you can manage how runs are added and executed.
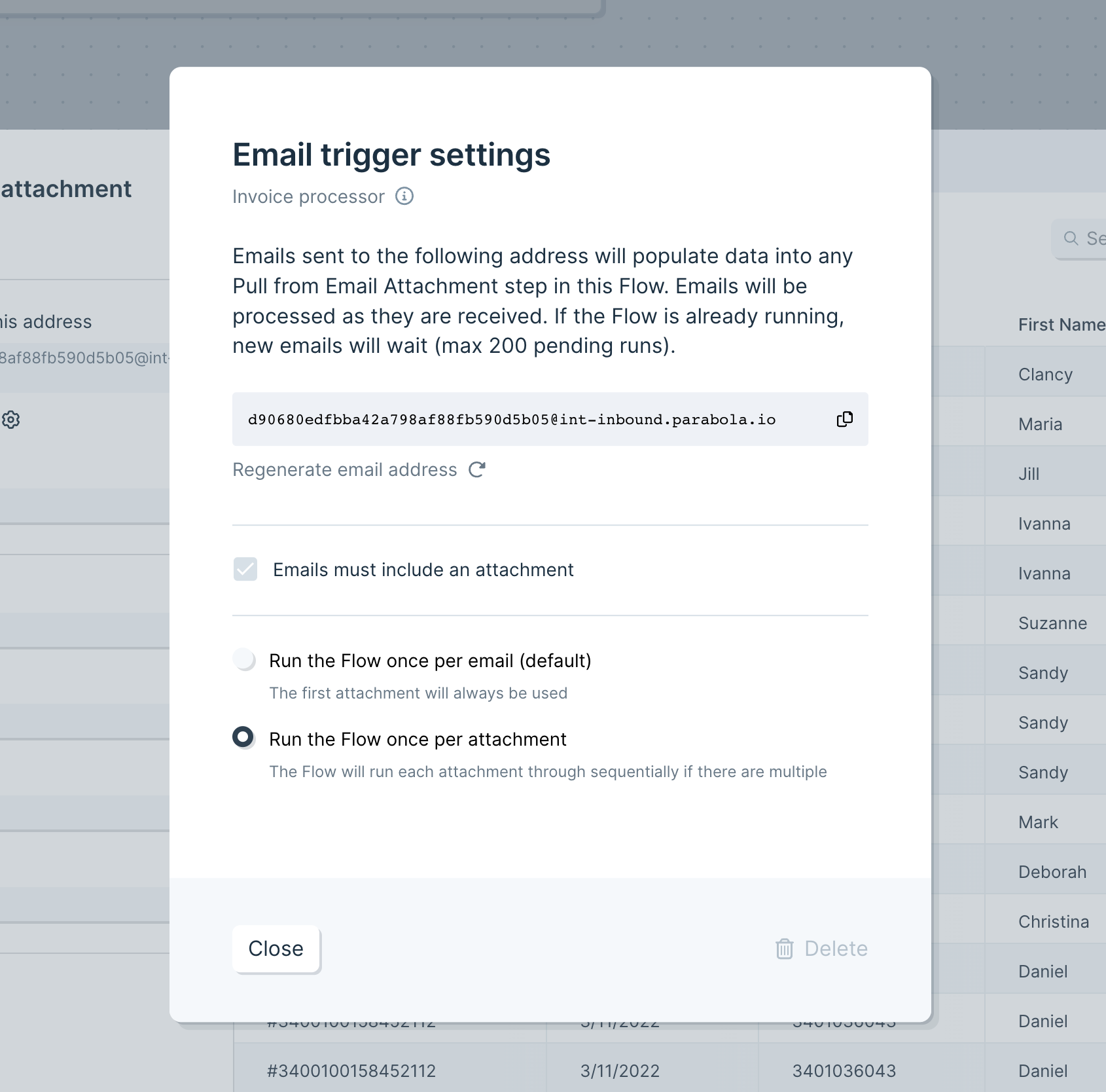

Improvement
Define custom formats for dates in Tables
Specify the format of any date column within a Table to improve the accuracy when changing its format.
.png)
Improvement
Access and re-use previous quick filters
Use the new “Recents” drawer in quick filters to access sets of filters that you have previously applied to tables and charts.
If you find yourself repeatedly filtering the same Flow, you’ll now be able to reapply those filters with one click.
We’ve also made filters easier to manage by adding a “clear” button, allowing you to instantly remove all applied filters.
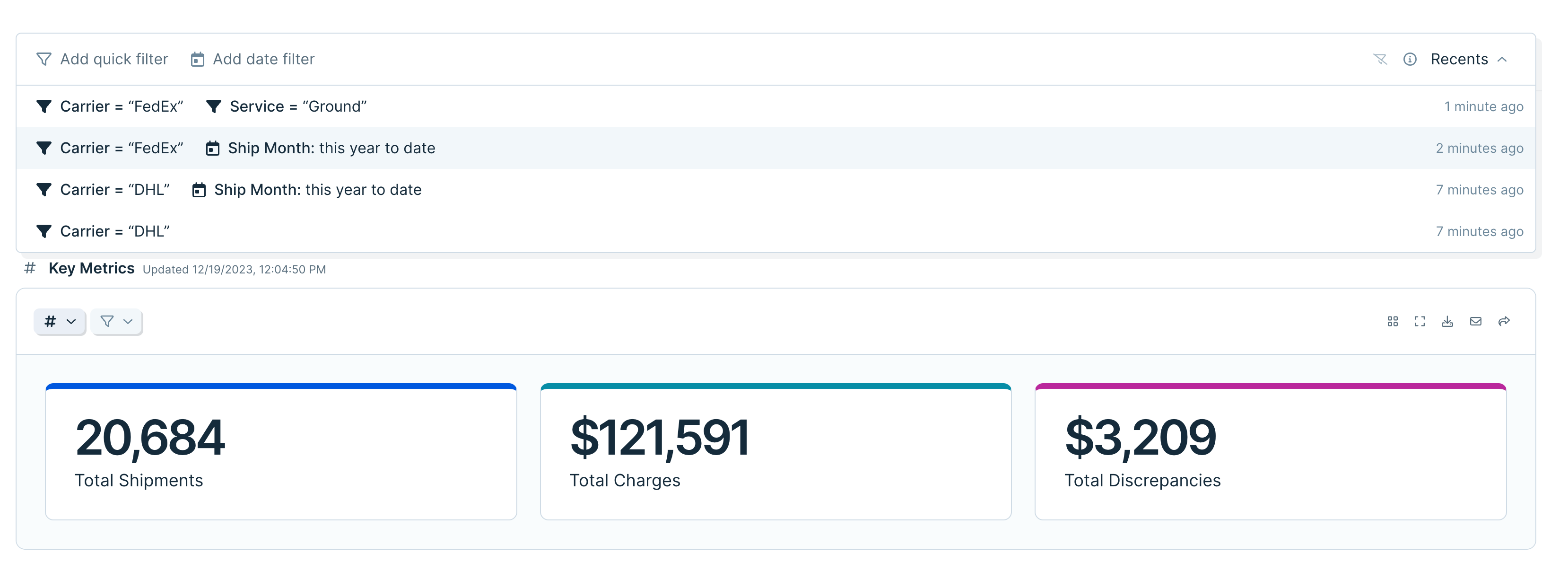
Improvement
Calculate NETWORKDAYS with Compare Dates step
The Compare Dates step can now calculate the difference between dates in terms of weekdays only, akin to the NETWORKDAYS function in spreadsheets. To use, select “weekdays” as your unit of measurement, and compare two dates (either two columns, or one column to current time). Here’s the handy documentation.
Improvement
Process entire folders of files using FTP
We’ve released a small but mighty feature to the Pull from FTP step!
The new “Archive file once processed” setting allows this step to cycle through a list of files in a folder, moving them after each one has been processed into a different folder.
Using this setting, you can build Flows that check folders for new files and process them one by one until the folder is empty.
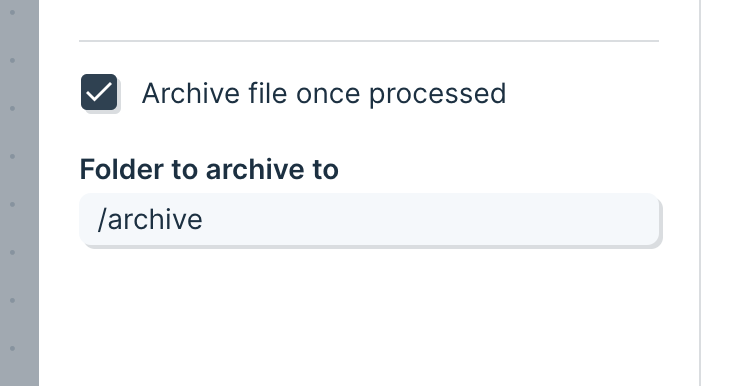
New
Send data to Snowflake
We now support sending data to Snowflake!
Snowflake is an essential repository for storing and accessing business data. Paired with our Pull from Snowflake step, Flows can be used to automate and collaborate on critical processes.
Read more in our documentation.
Send to Snowflake is available to customers on our Advanced Plan. Please contact us or schedule a call if you’re interested in them for your team!
New
Parabola Tables: now with Append, hiding, freezing, and links
Hot on the tails of our exciting release of visualizations, we’ve added three new features to Parabola Tables to make them more powerful for reporting.
Append and upsert
From the Send to Parabola step, you can now decide whether your data should:
- Overwrite on each run (existing functionality)
- Append new data to the bottom or top of your Table (new!)
- Update existing rows (new!)
This is great for anyone who is continuously adding new or updated data to their Tables, like week-over-week reporting.
Hiding and freezing
When looking at a Table on your published Flow page, you can now hide specific columns. These hidden columns can still be used within filters, sorts, or groupings for even more control over your final Table.
The first column and/or first row can also be frozen in place, so they “stick” while scrolling vertically or horizontally.
Use these to tailor Table views to exactly what you and your teammates want to see.
Automatic links
Any URLs in your Flow descriptions, Table descriptions, or even the cells within Tables will now be clickable.
Internally, we’ve found it incredibly helpful to add documentation links in our descriptions, and to easily access data that lives in another tool.
New
Introducing visualizations: Transform your workflow data into shareable reports
It’s a big day in the evolution of Parabola: we’ve added the ability to report on your data, empowering you to show your work more easily with data visualizations.

With visualizations in Parabola, you can:
- Keep everything in one secure platform – from the logic of your workflows to your reporting, to feel confident in the quality of your data and minimize manual work gathering information across systems and spreadsheets.
- Share important data with stakeholders through easy to read metrics that contextualize the output of your workflows and elevate your team’s work.
- Power agile reporting processes to transform ad-hoc analyses – like comparing data week over week – into automated, durable reports.
Take your data processes to the next level by building beautiful, shareable reports to share your work and make better decisions.
New
Request edit permissions to a Flow
Flow collaborators with view permissions can now request edit permissions at any time. Your request will be sent to Flow editors (or team admins, if necessary) for approval, and you’ll be notified via email as soon as your request is granted. The next time you open the Flow, you’ll have edit permissions!
You can initiate an edit request from two places within a Flow:
- The “Share” modal
- The viewer tool tip (hover over the “eye” icon)
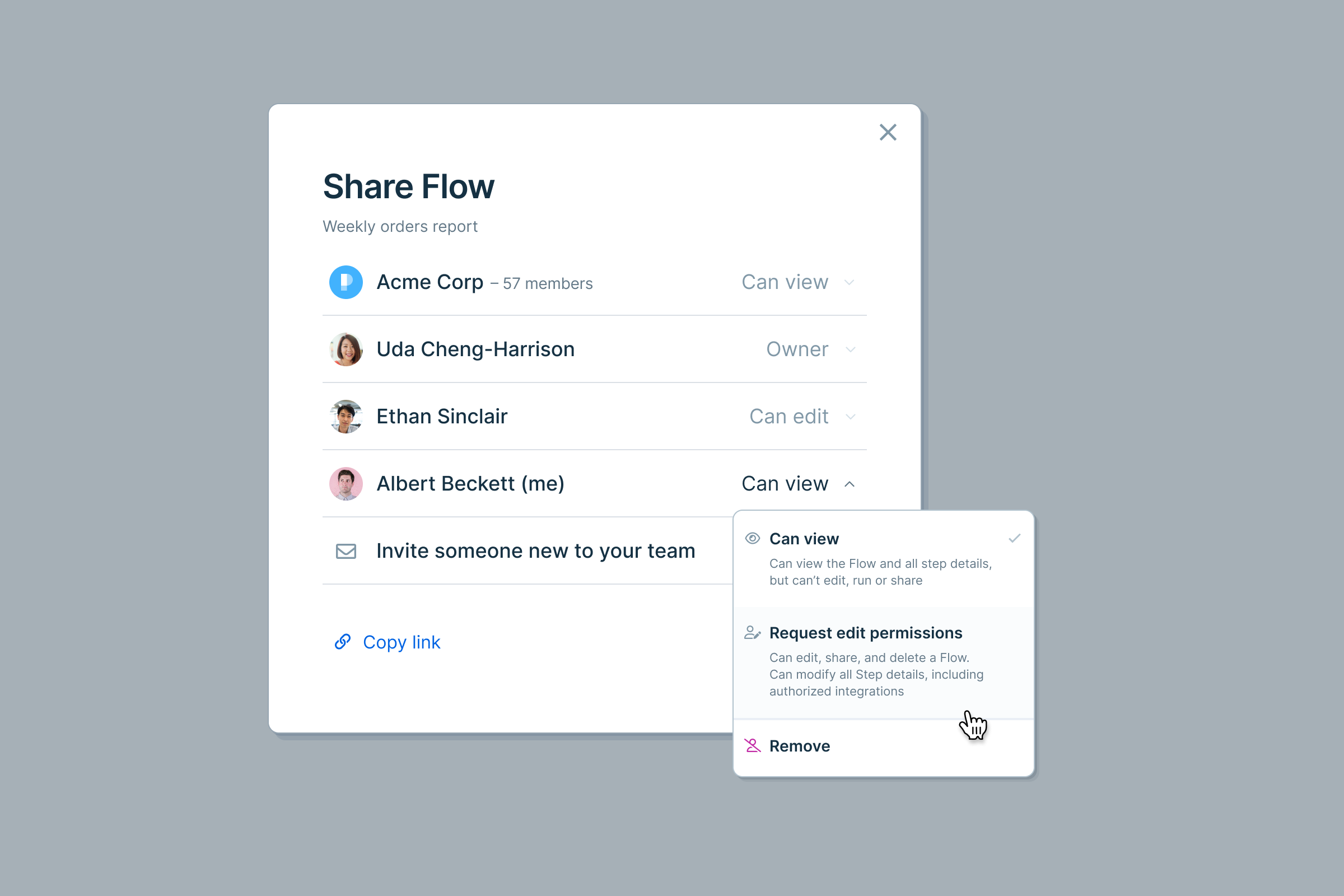

Improvement
Add descriptions to Tables to give your team more context
Custom Tables descriptions are now available on every Table, making it easier for Flow editors to provide context and instructions. Add descriptions to let your team know what data they can expect to find in each Table, how to best utilize it, and more.
