Connecting via API with with Apache Spark enables organizations to automate their large-scale data processing and analytics operations through the industry's leading unified analytics engine. This powerful connection allows businesses to streamline their data processing workflows while maintaining high performance and versatility, all through a robust API that supports complex analytics operations and machine learning pipelines.
How do I connect via API?
- Connect to the Spark API through Parabola by navigating to the API page and selecting Apache Spark
- Authenticate using your Spark credentials and configure necessary cluster settings
- Select the data endpoints you want to access (Spark SQL, MLlib, GraphX, Streaming)
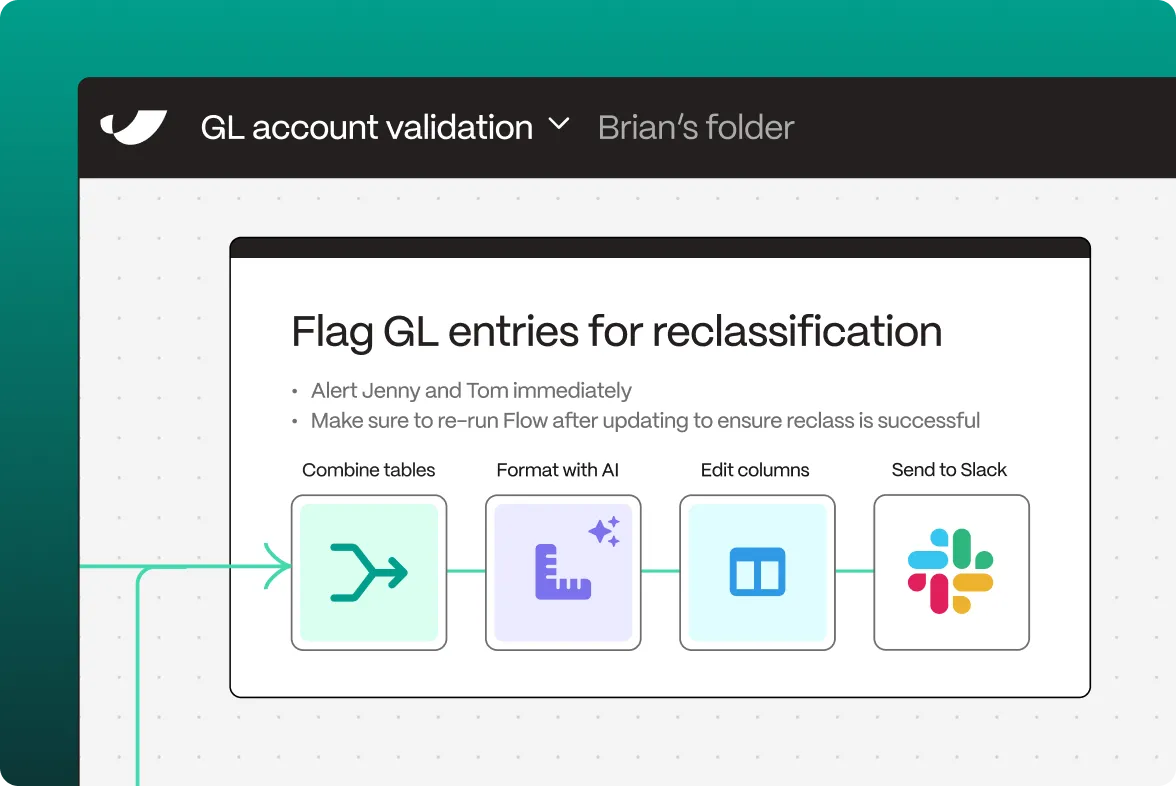
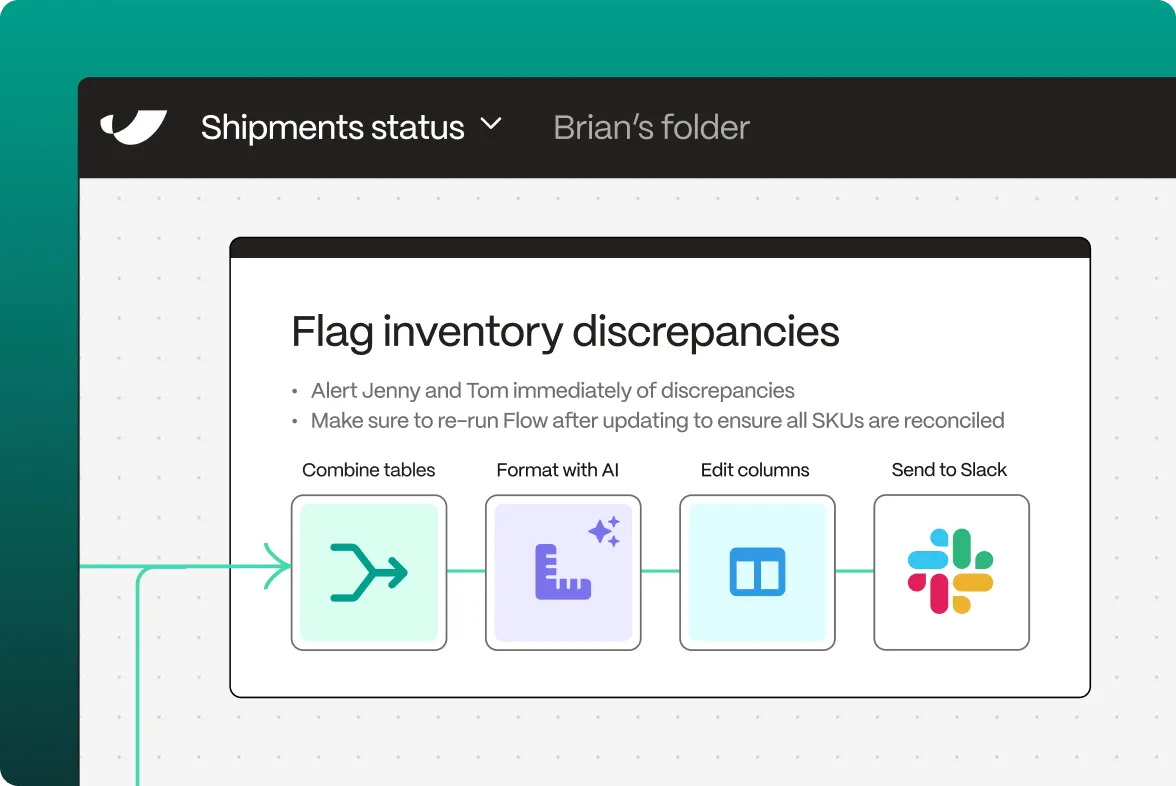
- Configure your flow in Parabola by adding transformation steps to process your data
- Set up automated triggers for batch processing and stream analytics
What is Apache Spark?
Apache Spark is a unified analytics engine for large-scale data processing, capable of handling both batch and real-time analytics workloads. Originally developed at UC Berkeley's AMPLab, Spark has become the de facto standard for big data processing, offering up to 100 times faster performance than traditional Hadoop MapReduce for certain workloads while providing a rich ecosystem for data analytics and machine learning.
What does Apache Spark do?
Apache Spark provides a comprehensive platform for distributed data processing and analytics, enabling organizations to perform complex computations across large datasets efficiently. Through its API, businesses can automate sophisticated data processing pipelines while leveraging Spark's in-memory computing capabilities. The platform excels in handling diverse workloads, supporting everything from SQL queries to machine learning and graph processing.
The API enables programmatic access to Spark's entire ecosystem, including Spark SQL, MLlib, GraphX, and Structured Streaming. Organizations can leverage this functionality to build automated analytics pipelines, deploy machine learning models, and process streaming data while maintaining high performance and scalability.
What can I do with the API connection?
Data Processing Automation
Through Connecting via API with with Spark, data teams can automate complex data processing workflows. The API enables scheduled batch processing jobs, automated data transformations, and seamless integration with various data sources. This automation ensures efficient data processing while maximizing resource utilization.
Machine Learning Pipeline Management
Organizations can leverage the API to automate their machine learning workflows. The system can handle model training, validation, and deployment processes while managing the entire ML lifecycle. This automation helps streamline machine learning operations while maintaining model performance and reliability.
Real-time Analytics
Analytics teams can automate their real-time processing workflows through the API connection. The system can process streaming data, generate real-time insights, and trigger automated actions based on analysis results. This automation enables responsive decision-making while maintaining processing efficiency.
ETL Process Optimization
Data engineers can automate their ETL processes by leveraging Spark's powerful transformation capabilities through the API. The system can manage complex data transformations, handle data quality checks, and ensure efficient data loading into target systems. This integration streamlines data preparation while maintaining data quality and consistency.
Performance Monitoring
System administrators can automate their Spark cluster monitoring and optimization tasks through the API. The system can track job performance, manage resource allocation, and optimize query execution plans. This automation helps maintain optimal performance while reducing operational overhead.
Through this API connection, organizations can create sophisticated data processing workflows that leverage Spark's powerful capabilities while eliminating manual operations and reducing complexity. The integration supports complex analytics operations, automated machine learning pipelines, and seamless ecosystem integration, enabling teams to focus on deriving insights rather than managing processing infrastructure.