Give teams what they need without losing control.
Parabola is an AI-powered workflow builder that empowers teams to build reports, automations, and custom logic on top of your existing systems—without creating more work for data and engineering.

















Custom reports and one-off asks distract from high-priority work, but no one wants to be the one to say no. Empower non-technical teams to build their own automations without adding to your queue.
Business teams don’t want to adopt AI alone… but they will if they have to. Be the partner that helps them adopt AI safely and effectively with the guardrails, access, and advice they need.
When teams upload CSVs to ChatGPT, there’s no visibility into how your data’s being changed. With Parabola, every workflow is auditable, permissioned, and version-controlled—just like code.
Empower your business teams to
build scalable processes.
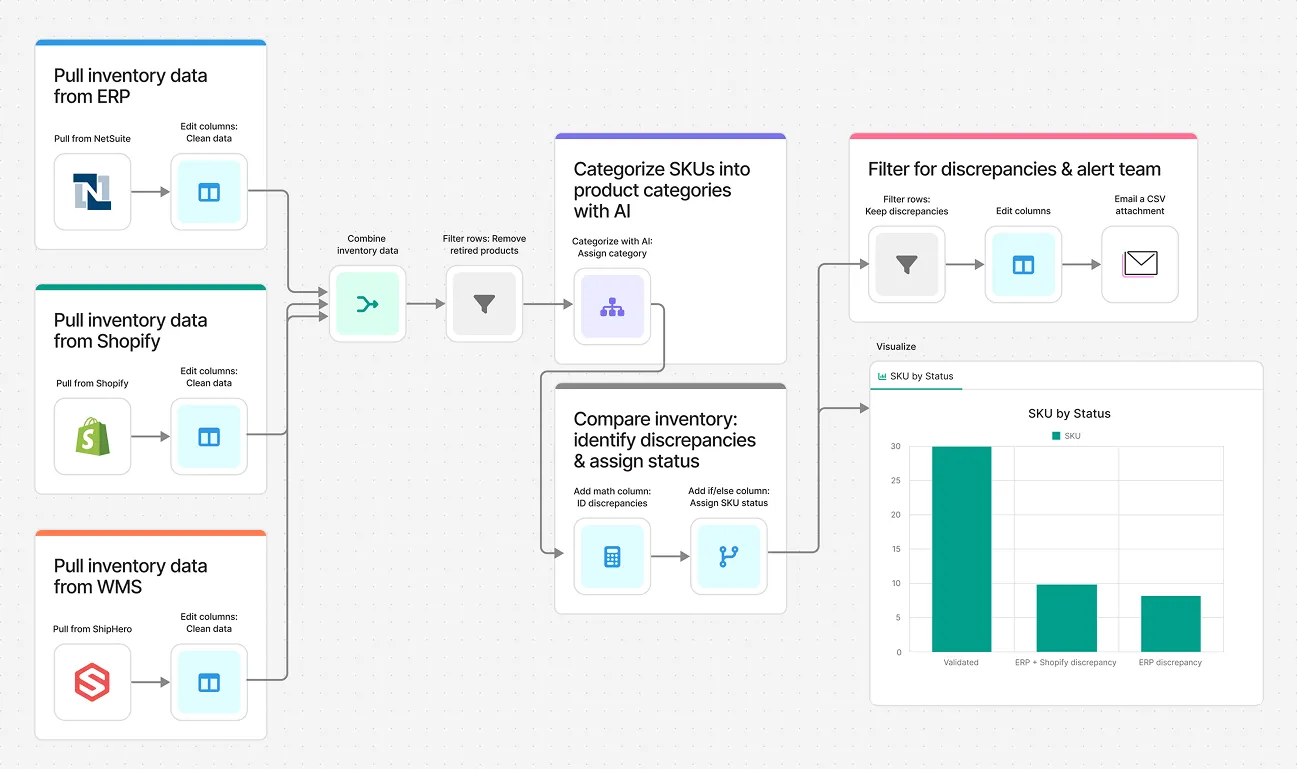
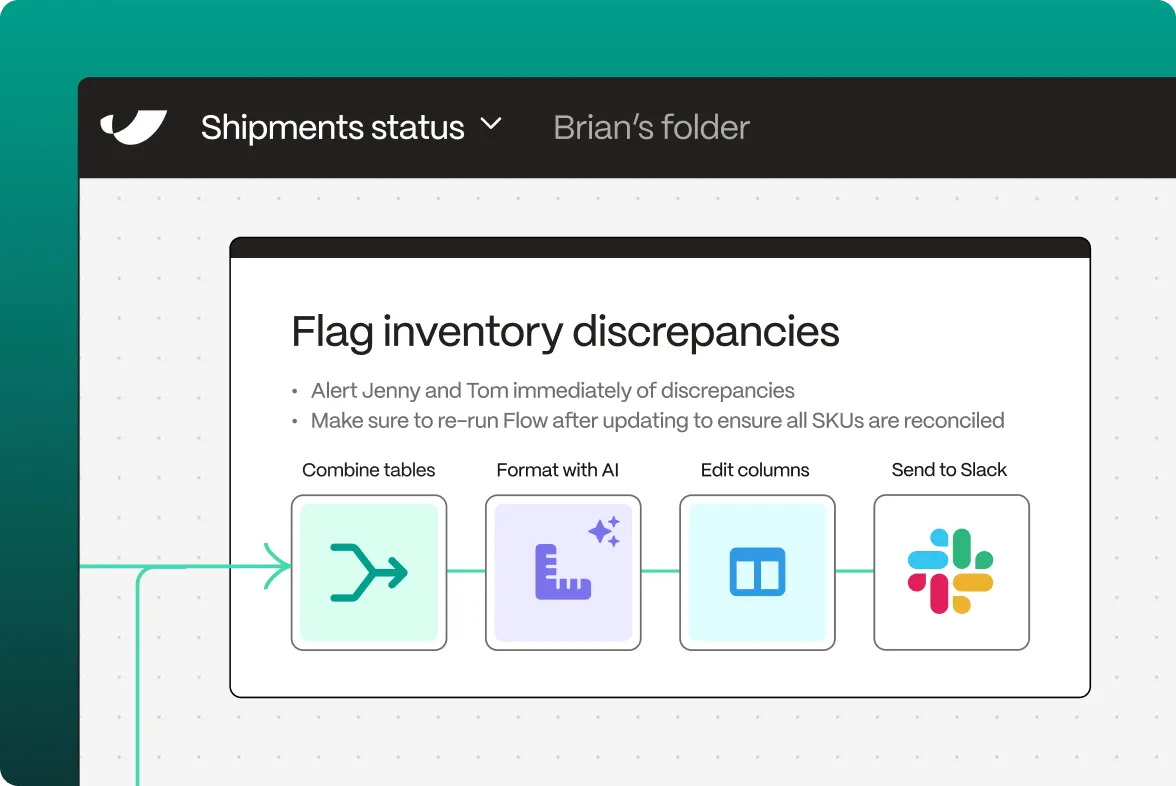
Compare inventory across your ERP, WMS, and sales channels like Shopify. Spot discrepancies and trigger alerts before you’re out-of-stock or over-allocated.
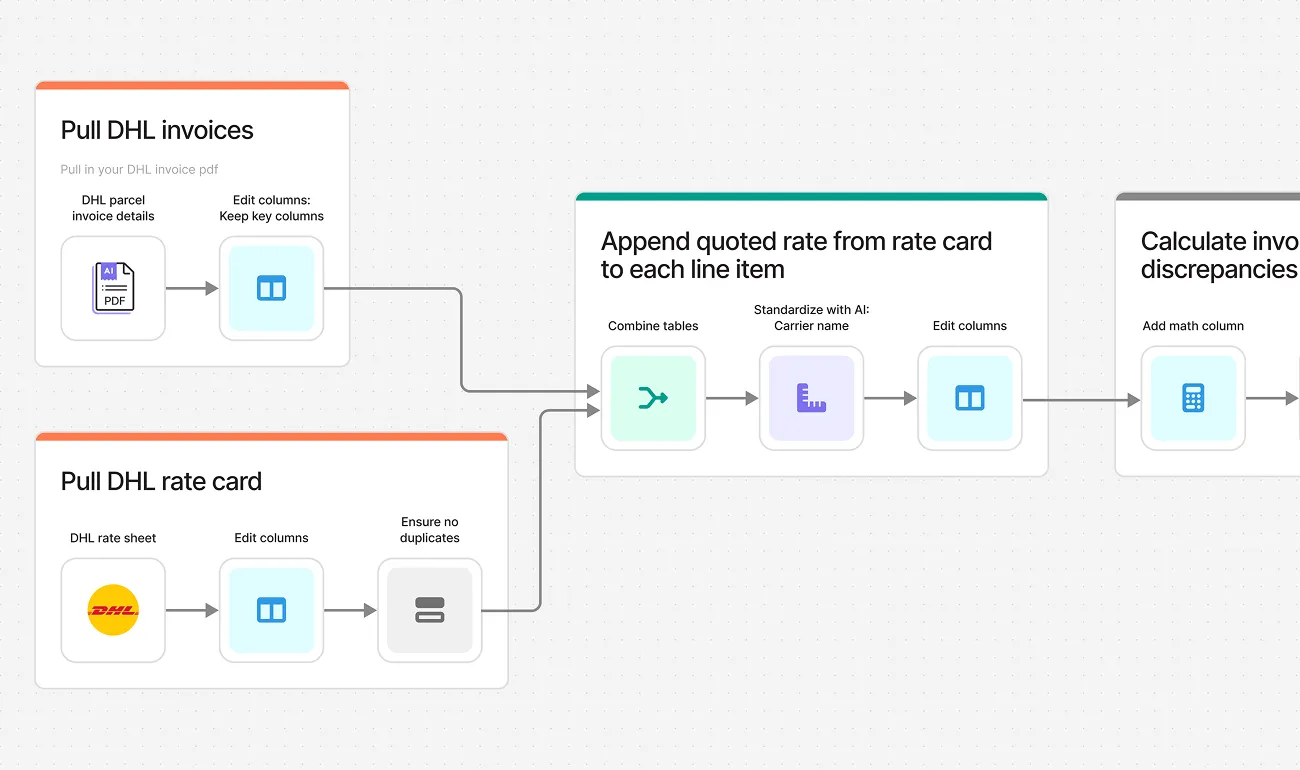
Parse PDF invoices from carriers, compare charges against rate cards, and surface overages and errors—without spending hours reviewing line items manually.
Centralize shipment data from carrier APIs, emails, and spreadsheets. Automatically update statuses and ETA changes and give your team a single source of truth.
Combine and standardize orders from sales channels like Amazon, SPS, and email. Drive visibility into SKU-level sales by channel and speed up financial reporting.
Bring together order and shipment data from your ERP, Shopify, 3PLs, and carriers. Automatically flag potential SLA breaches before they impact the customer.
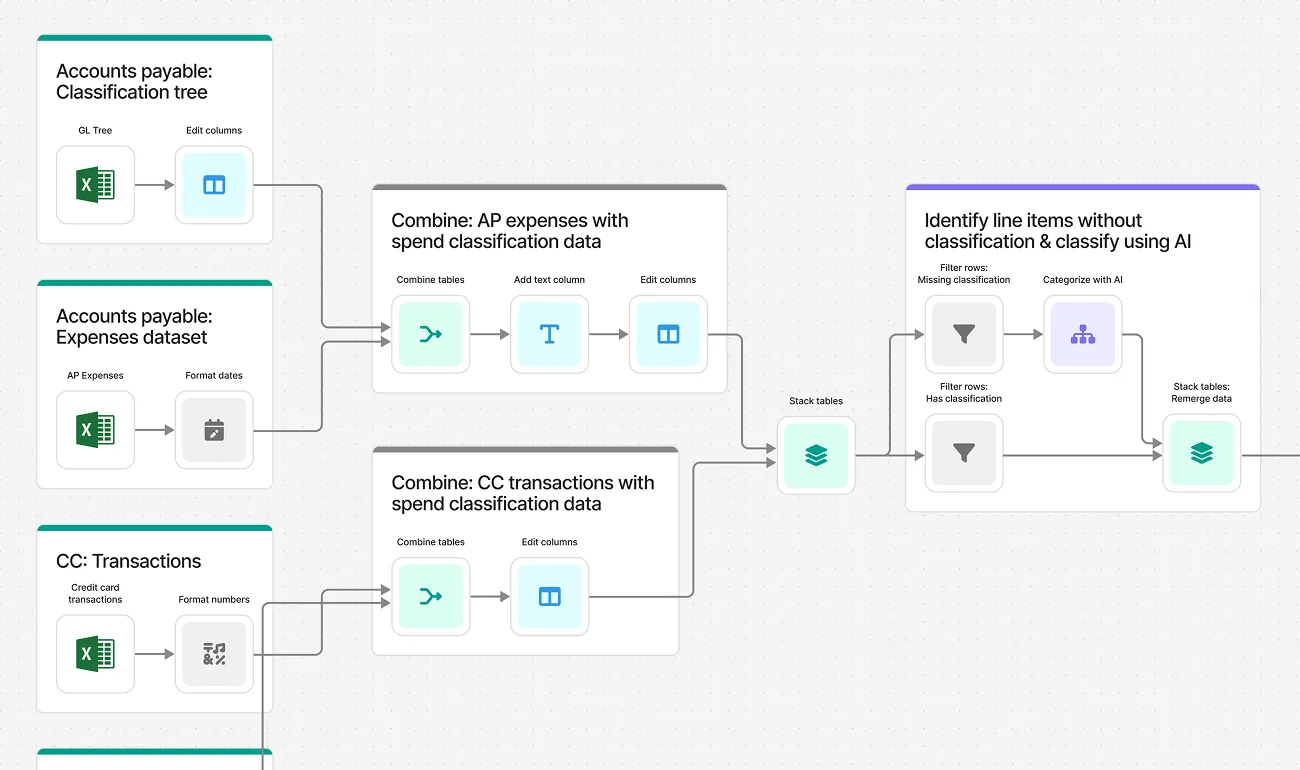
Parse supplier PDFs and reconcile POs, receipts, and invoices at scale. Identify mismatches automatically and reduce manual review across your AP process.



See what our customers have to say.

"With Parabola, my team spends less time setting up reports and more time focusing on our core job requirements – eliminating human error and saving tons of time.”


The ops team has become so dependent on Parabola—it has helped our workflow a lot.


We use Parabola to automate data transfer, billing reconciliation, and real-time alerts. With Parabola's robust and simple data connection features, we're able to save a ton of time and work – for both my team and the IT team.


With Parabola, we connect to the tools that our data team is actually using. This expands the problems we can solve with Parabola and contributes directly to millions in revenue and profit growth.

Improve governance and move 10x faster.


Prove ROI before you're invoiced.
Too many teams commit to software they never end up using. That’s why we offer a 30-day proof of concept. Build something real with our team and only become a customer if there’s value.
Turn messy data into automated workflows.

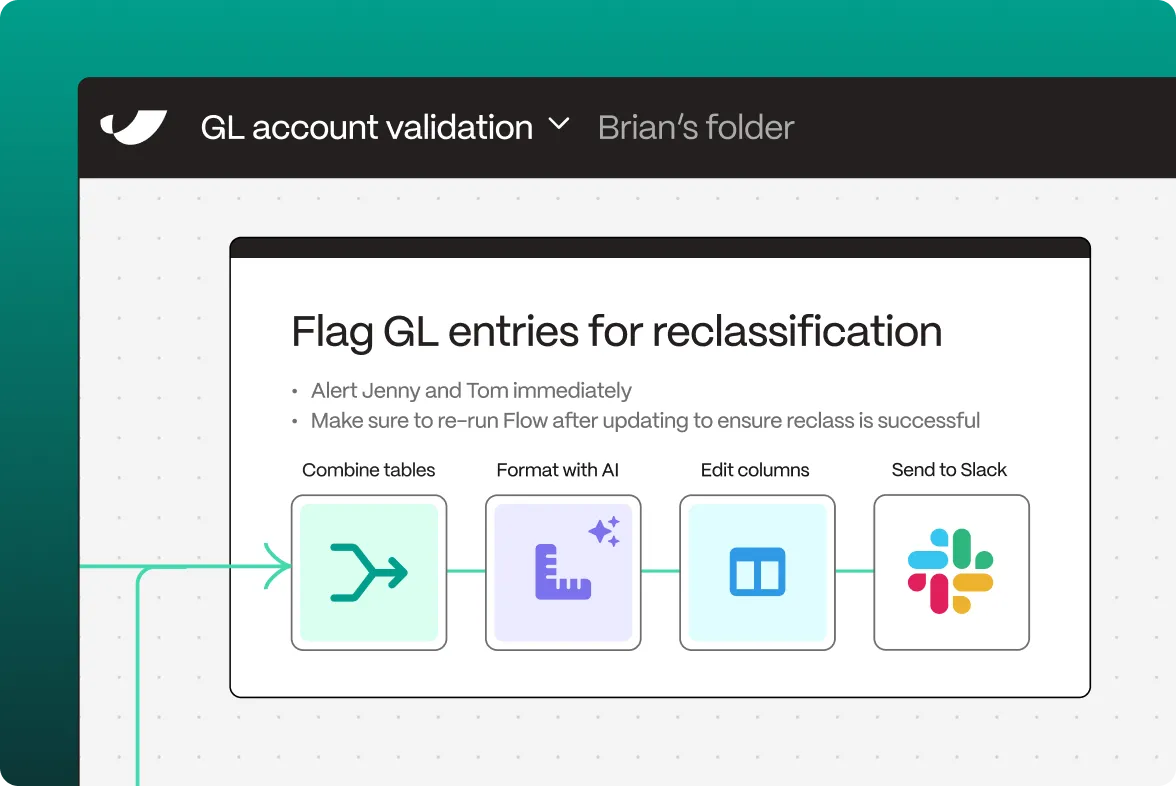

Enable business teams to tap into the systems you’ve set up without the CSV exports. Supervise reverse-ETL workflows from Snowflake, Looker, Redshift, and everything in between.
Custom, one-off logic that changes every other week isn’t meant for code. Capture your business logic in flexible workflows and apply updates in seconds when requirements change.
When operations and finance teams can set up automations independently and tech teams aren’t slowed down by interrupt asks, everyone moves faster.
Connect any system, automate every workflow.

Don't just take our word for it.
See how leading brands use Parabola to automate their complex data workflows.
.png)







Frequently asked questions
Yes. Parabola is SOC2 Type II compliant and trusted by brands like Flexport, Coca-Cola, Brooklinen, and On Running.
Parabola integrates with virtually any system. In addition to 50+ native integrations like NetSuite and Shopify, Parabola offers an API and the ability to integrate via email—making it easy to connect to systems like ShipHero, Snowflake, Redshift, FTP folders, and more. You can also connect to thousands of tools and work with unstructured data like emails and PDFs.
The best Parabola use cases are recurring processes that involve complex logic and messy data coming from multiple data sources.
Parabola is most commonly deployed across operations, supply chain, finance, accounting, procurement, and data teams. Any team regularly working with data can see value from Parabola by working faster with improved visibility.
We offer two approaches to starting with sample data. After signing up for an account, you can ask Parabola, “Help me get started with sample data,” and you’ll be provided with a selection of 10+ sample datasets. Alternatively, use our secure anonymization tool to strip your data of sensitive information before uploading.
Finance and accounting teams across On Running, Cart.com, Brooklinen, Faherty, and Flexport use Parabola to automate the work they thought would always be manual. Explore more on our customer stories page.