
Deduplicating across lists is a common, but surprisingly difficult task. You have two lists of client ids but only want the unique ones across both lists; or you want the inverse: which ids from the first list aren't present in the second? Parabola's list contains step makes this sort of work easy.
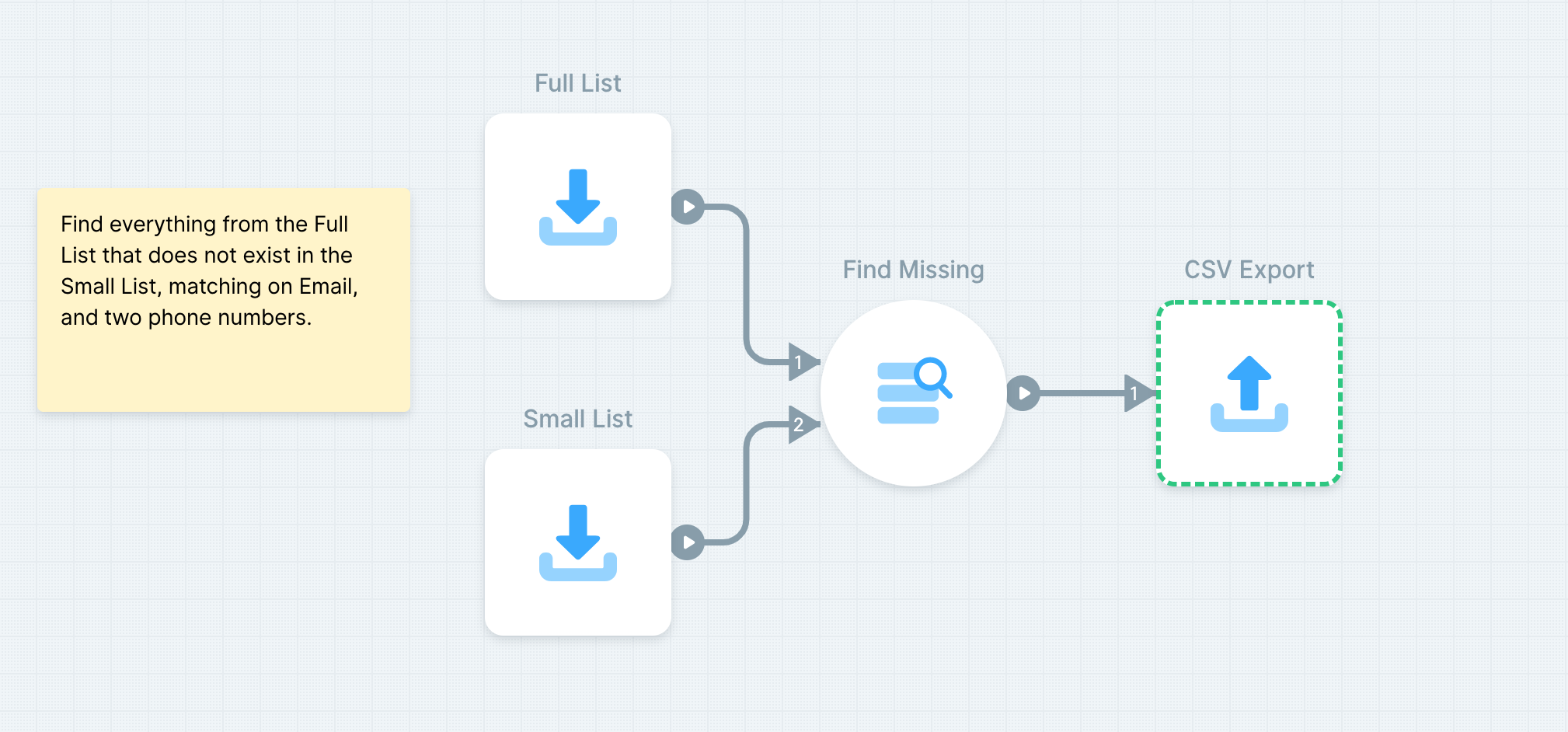
The main logic in this flow comes from Parabola's Find overlap step. That step takes as input two lists, and outputs entries that match the conditions specified in its settings panel. By default the step will output entries that appear in both input lists, but settings allow lots of flexibility:
–You can add arbitrarily many rules, i.e., match items along multiple conditions.
–The step can output items that do not match any or all of your rules.
–The step can be configured to be case sensitive or case insensitive.
–You can use fuzzy matching as part of rules, and can optionally configure the fuzziness as a percentage.
–For debugging, the step can be configured to output a column indicating how a match was achieved.


