Three ways to bring a PDF into a flow
- Upload directly with the Extract from PDF step — best for one-off files.
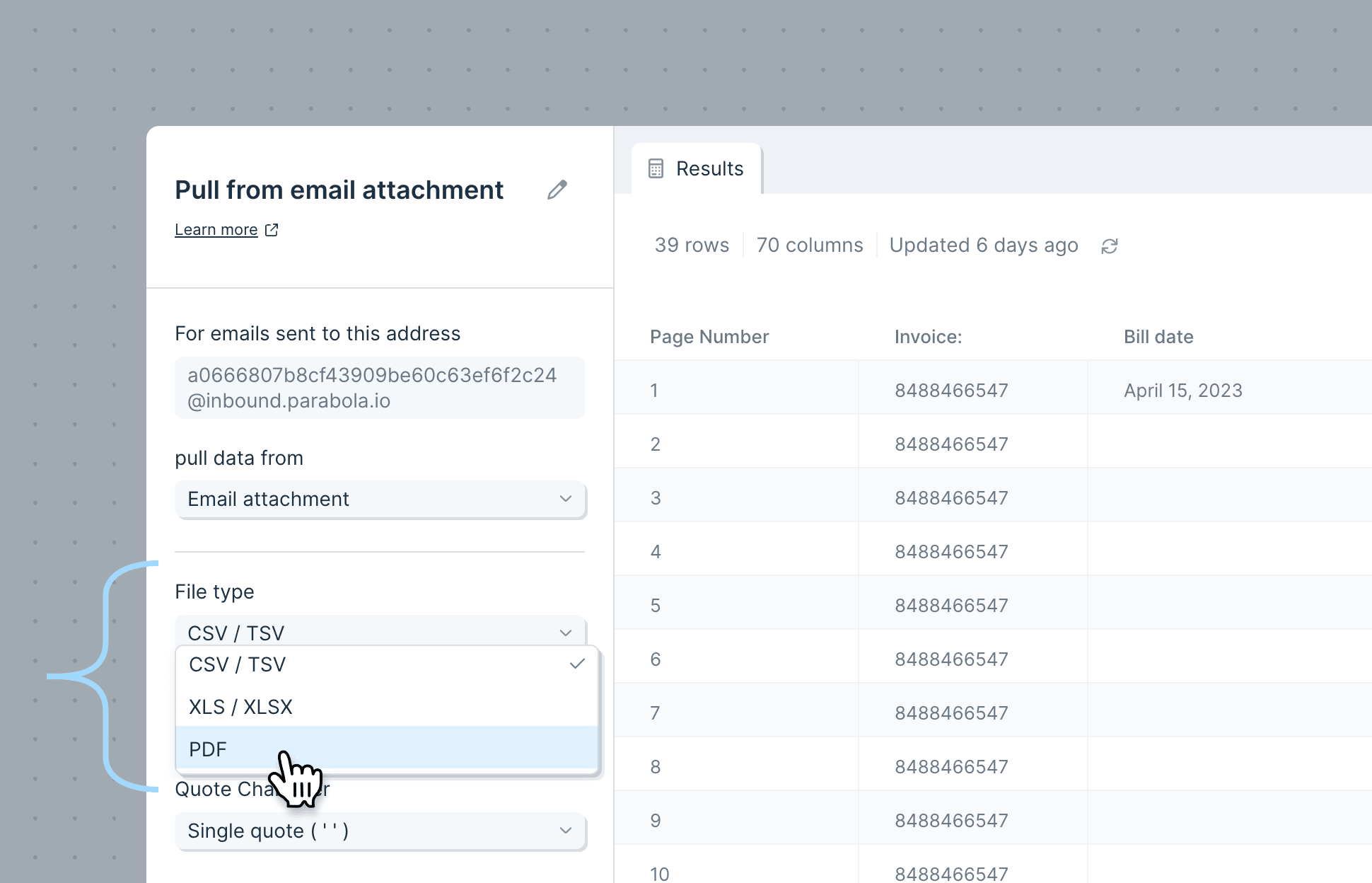
- Pull from inbound email with Extract from email — best when partners or vendors send PDFs by email.
- Process in bulk with Pull from file queue — best for batch processing many PDFs accessible via URL.
Columns vs. keys
The parser returns data as columns or keys:- Columns are values that repeat down the document — line items in an invoice, rows in a packing list.
- Keys are document-level values that appear once and apply to the whole document — invoice number, PO date, total.
- The AI sometimes flips the two. If a value isn’t pulling correctly, try the other option.
- Both accept extra context (descriptions, examples, instructions) to improve accuracy.
Pick a parsing method
Auto-detected table (default). Parabola scans the PDF, finds candidate tables, and labels likely columns. Quickest setup; works best when the document has clear, headered tables. Detected tables show up under “Use an auto-detected table.” You can add columns or keys manually after. Custom table. Define the table structure by hand if auto-detect didn’t catch it. Name the table and add columns with + Add Column. Best for multi-table documents and tables that span pages — more setup, more control. Extract all data (OCR-first mode). Returns all text from the PDF using OCR. Use only when the first two methods don’t return what you need, or when you plan to feed the result into another AI step downstream. Return formats:- All data — every value, one per row
- Table data — tables split by page, each with a table ID
- Key-value pairs — labeled items like
SKU: 12345 - Raw text — one cell per page, useful for follow-up AI parsing
Extract values
For document-level fields like invoice number or PO date, add them under “Extract values” with + Add key. Each key becomes its own column with the value repeated across every row.- Names can be descriptive — they don’t have to match the PDF text exactly. Pick something the AI can connect to the field.
- Examples are the highest-leverage way to improve accuracy.
- “Additional instructions to find this value” is optional but helpful for tricky cases. Example: to split an order ID like
ABC:123into two columns, instruct the parser to “Take the order ID and extract all of the characters before the ’:’ into a new column.”
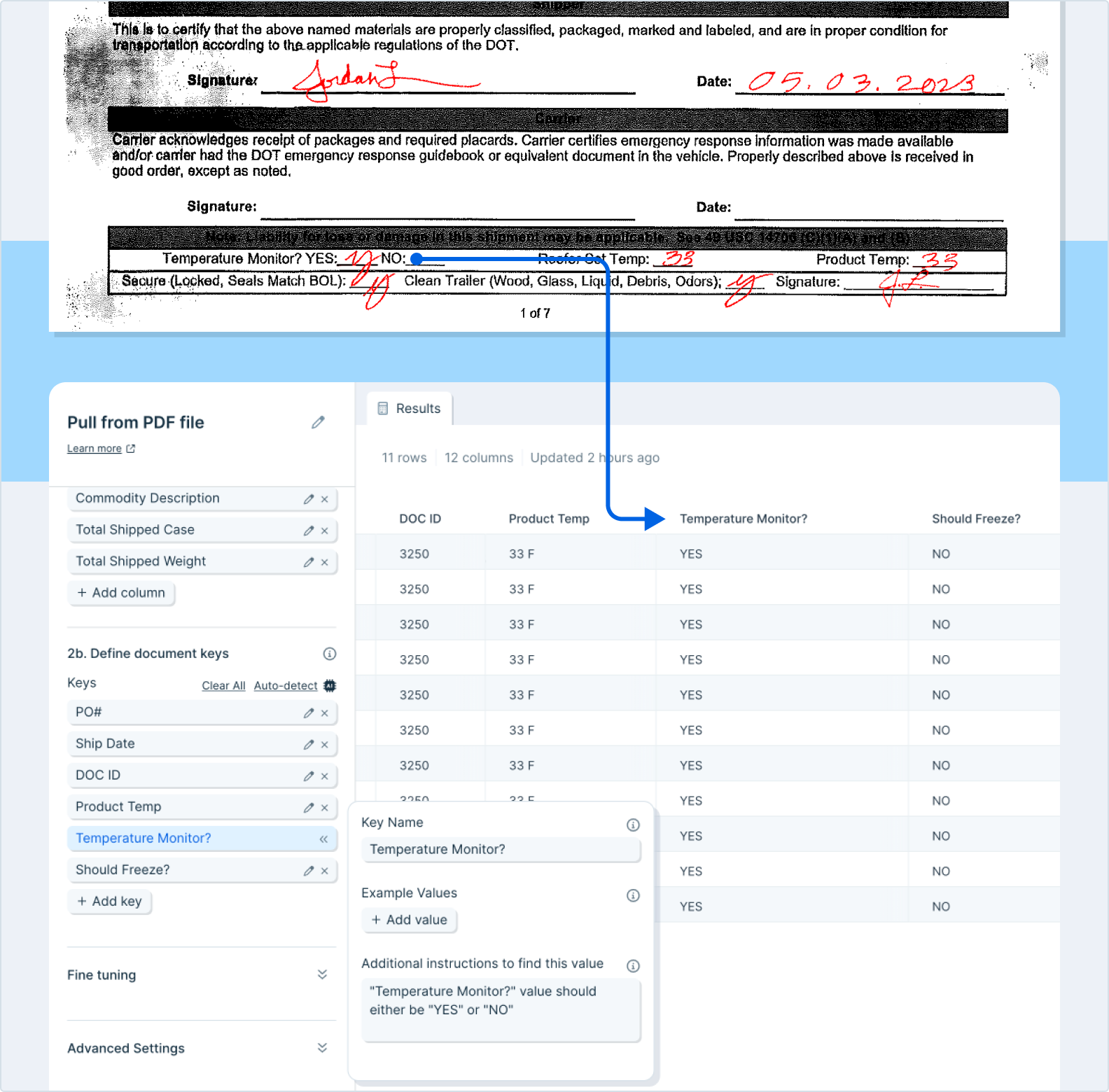
Fine tuning
Add overall context and instructions in the fine-tuning text box. Specific examples and clear scenarios outperform vague guidance. The chat panel on the left can help you draft the prompt.Advanced settings
Text parsing approach. Default is “Auto.” Other options:- OCR — slower, better for handwriting and complex scans
- Markdown — generally faster, often works better on PDFs with nested columns
- Keep, Remove, or Autodetect — Autodetect lets the parser pick pages
- The first / the last / these — set a number for “first” or “last,” or list specific pages (e.g.,
1, 10, 16)
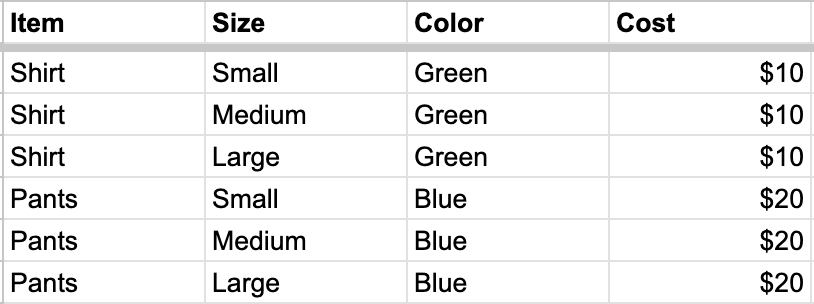
Child columns
Mark a column as a “Child column” when its values don’t repeat with the parent — for example, sizes within a product line. Before: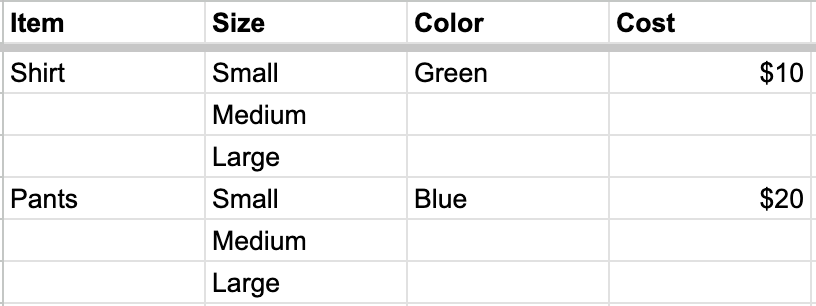
Tips & limits
- Fewer pages parsed = faster runs. Use page filtering when you only need data from a few pages.
- Multiple tables in one file usually need multiple PDF steps — one per table.
- File limit: under 500 MB and 30 pages.
- PDFs cannot be password-protected.
- Always audit AI-parsed results before relying on them.
Choosing the right step
For a single one-off PDF, drag a file onto the canvas to use the Extract from PDF step.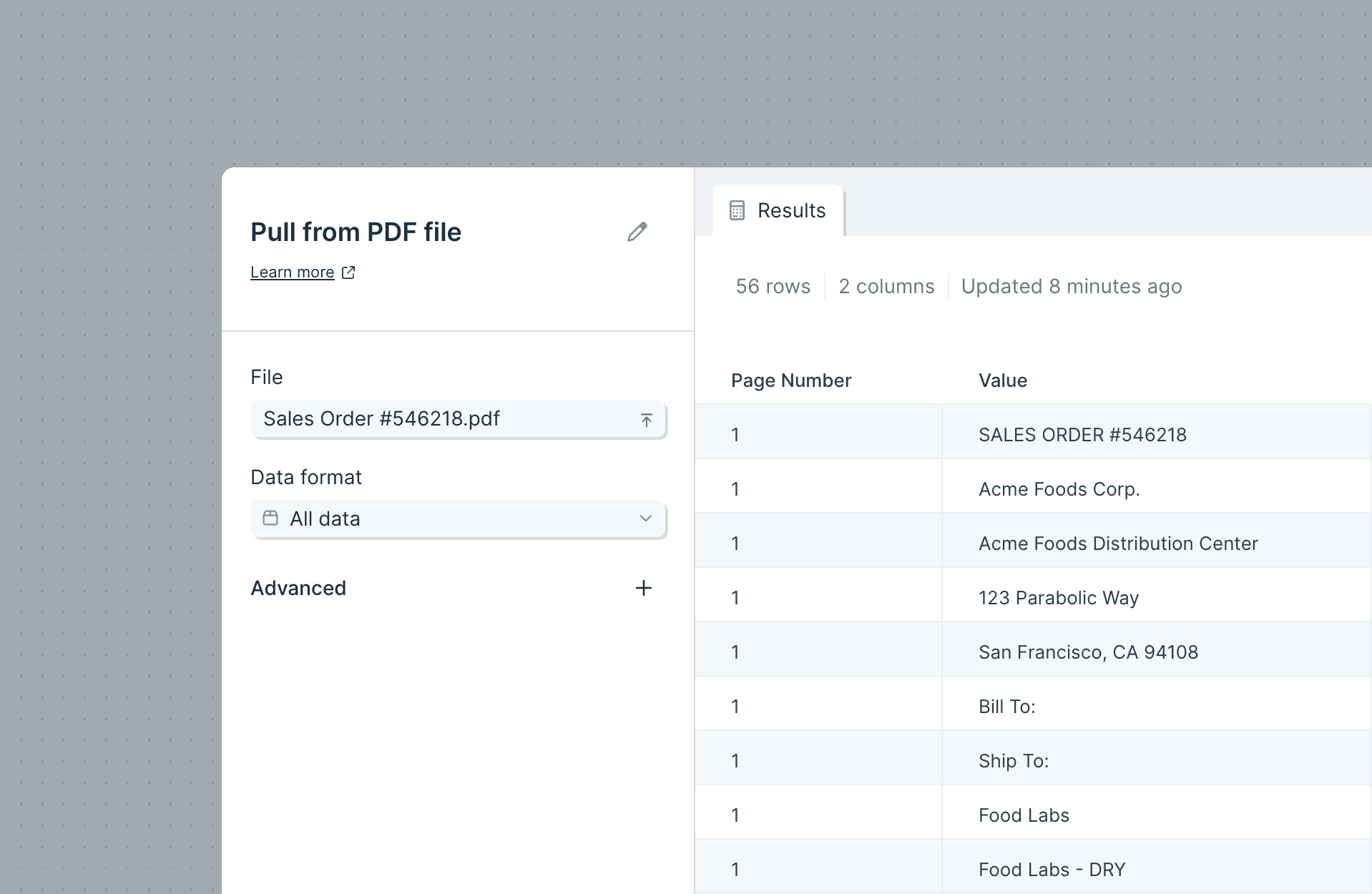
Related steps
- Extract from email — for PDF attachments coming in via email
- Pull from file queue — batch process many PDFs
- Run another Parabola flow — chain a queue-based parsing flow off another flow
- Extract with AI — pull additional fields from already-parsed text
- Categorize with AI — classify parsed line items